Introduction
This is the documentation for BFO Publisher ${VERSION}, the HTML to PDF converter from https://publisher.bfo.com
BFO Publisher is a CSS Layout engine. It takes HTML or XML as input, applies a CSS stylesheet to it to lay out the elements on one or more pages then writes the result to a PDF, just as a web browser would write the results to your screen.
Here are some highlights:
-
Input formats:
-
HTML5, SVG2, MathML4 or generic XML.
-
Anything we can convert to HTML, such as EPub, plain-text or AsciiDoc
-
Embed SVG, bitmaps, video, audio, barcodes, 3D models and PDF. Here’s the list.
-
All the worlds languages supported. Well, not traditional Mongolian, but all the others.
-
-
Output formats:
-
PDF and PDF 2.0. PDF/A-1, A2, A3 and A4, PDF/X and best-in-class support for PDF/UA with full control over tags and attributes.
-
SVG, including options for multi-page files.
-
Any bitmap format, created from the PDF.
-
-
Input rigorously tested against the web platform tests, also used to test browsers. Accurate support for CSS2.1 - passing 98.6% of tests, about the same as your browser means tables look the same in pdf as they do on screen.
-
Comprehensive CSS3 support: selectors-4, cascade-5, color-5, fonts-4, backgrounds-3, images-4, shapes-2, page-3, gcpm-1, flex-1 and many more.
-
Built on our PDF Library, it generates PDF/A and PDF/UA files that are verified as correct.
-
Digital signatures, including PKCS#11 keystores, Amazon Cloud HSM and the GlobalSign digital-signing service.
-
HTML5 forms are as supported as we can make them!
-
Streaming model means ten-thousand page documents are no problem.
-
XSLT and XInclude support.
-
HTTP or WebSocket-based web-service option to do all of this on a remote host.
-
100% home-grown Java. No native code, minimal third-party libraries. Multi-thread ready with smart caching for batch conversions.
This document will show you how to do all of the above. However it will not go into heavy detail on CSS itself, as it uses the same CSS layout rules as Firefox, Chrome and Safari. It’s normal CSS. Rather than repeat all of that here, this document will focus mainly on the extensions and differences that make BFO Publisher unique, as well as some of the lesser known areas of CSS that are required for layout to paged media. There are a million guides on the internet for CSS, so you can pick your favourite (we recommend https://developer.mozilla.org/en-US/docs/Web/CSS/Reference) or head to https://www.w3.org/Style/CSS/ for the source.
As well as what we can do, here’s what we can’t do: we’d rather you hear it from us, as it may save you some time.
-
No JavaScript! Why? Because we don’t have a DOM. BFO Publisher is is built around the concept of streaming, so XML elements are fed in, styled, put on the page and discarded. The entire document is never in memory, which means if you want to lay out a million row table, you can (it’s 20,200 pages of A4: with 175MB of heap it takes just under two minutes on a modern laptop). Losing JavaScript is the price we pay for that ability.
-
PDF is not interactive, so has no support for scrollable areas, animation, mouse-hover styling and similar.
-
HTML forms use a very different model to PDF forms; we map as close as we can.
-
Special elements like
<video>and<audio>are more limited in PDF than in HTML -
Quirks mode layout is not supported
-
Variable OpenType fonts are not supported in PDF.
-
For CSS layout, see our release notes for the list of known issues.
Overall, if your file has no JavaScript we should be able to lay it out into PDF pretty much exactly as you’d see it on screen.
Quick Start
There are three ways to use BFO Publisher: build an application with the API, run the Web Service and control it with HTTP or WebSockets, or run it from the command line (easiest, but also slowest due to Java’s start-up time and the need to reload the system stylesheets and fonts for each conversion).
Command Line
Download the application, unzip, then run command below.
# For help on the CLI interface
$ java -jar bfopublisher-bundle.jar --help
# As above, but include extra JAR files in the classpath
$ java -cp bfopublisher-bundle.jar:path/to/otherjar.jar org.faceless.publisher.Main --help
# To run the web-service
$ java -jar bfopublisher-bundle.jar --web
# An example conversion
$ java -jar bfopublisher-bundle.jar --format pdf --input input.html --output out.pdfGUI
Download as above but double-click on the bfopublisher-bundle.jar. The application will
run as a web-service with an icon in the System taskbar.
The comand java -jar bfopublisher-bundle.jar --web-gui may also be used to start
the application in this way.
Docker
Run the command below and then connect to the exported web interface
# run application normally
$ docker run -P -d bfocom/publisher
# as above, but add any JAR files in "/local/jarpath" to the classpath
$ docker run -v /local/jarpath:/var/publisher/jars -d bfocom/publisherAPI "Hello World" example
Create the following in the file Converter.java
import java.io.*;
import org.xml.sax.SAXException;
import javax.xml.parsers.ParserConfigurationException;
import org.faceless.publisher.ReportFactory;
import org.faceless.publisher.Report;
import org.faceless.publisher.output.ReportOutput;
import org.faceless.publisher.type.MediaType;
public class Converter {
final ReportFactory factory = new ReportFactory();
public static void main(String[] args) throws Exception {
new Converter().convert(new File(args[0]), new File(args[1]));
}
public void convert(File infile, File outfile)
throws IOException, SAXException, ParserConfigurationException
{
Report report = factory.createReport();
ReportOutput output = factory.createReportOutput(MediaType.parse("application/pdf"));
report.setReportOutput(output);
report.load(infile);
report.parse();
FileOutputStream stream = new FileOutputStream(outfile);
output.write(stream);
stream.close();
}
}Compile and run:
$ javac -cp bfopublisher-bundle.jar Converter.java
$ java -cp bfopublisher-bundle.jar Converter:. helloworld.html helloworld.pdfHTML vs. XML
XML should be very well understood by any developer, and in particular its use of namespaces. BFO Publisher’s native input format is XML, and we ship with CSS stylesheets for formatting the XML namespaces most commonly associated with CSS: HTML, SVG, MathML.
HTML is similar enough to XML that it’s often indistinguishable.
However there are some important differences between the two which anyone using
BFO Publisher should be aware of.
In fact, they’re important enough that our number-one rule is:
know whether your file is being parsed as HTML or XML:
BFO Publisher chooses the XML or HTML parser depending
on the Media Type of the file (as set by the HTTP Content-Type header, for example),
or the URL suffix if the Media Type is unknown.
If it still can’t be determined the API will guess, and like most guesses it will sometimes be wrong. So always ensure the Media Type or URL can be use to determine the file type.
| XML Parsing uses the Java SAX implementation, and the one supplied with the JVM is normally the best choice, and in Java 17 or later it is one of the fastest too. In older JVMs the BFO SAX parser at https://github.com/faceless2/sax and the Woodstox parser at https://github.com/FasterXML/woodstox are certainly faster, so if speed is an issue they’re worth a try. We do not recommend the Apache Xerces parser - this has a number of issues which seriously impact performance, and some outright bugs. Do not use it. HTML parsing requires the parser from http://about.validator.nu - the 1.4 build is very old but works well, and later builds from trunk should be fine too. |
| XML | HTML |
|---|---|
Media type of |
Media type of |
Default encoding of UTF-8 may be overridden with an initial |
Default encoding of ISO-8859-1 may be overridden with a |
Case-sensitive. |
Case-insensitive. Attributes or elements which are defined as mixed case (only a few, all in SVG) are handled specially by the parser, the rest are lower-cased internally. |
XML requires text and attributes to escape |
No escaping is required. The parsing rules vary by element, which allows |
Processing instructions can be used, such as |
Processing instructions are not part of the HTML language. |
Elements must be either self-closed or closed with an explicit close tag. |
Elements do not need to be closed, although it’s often good practice. Self-closing tags are not part of the HTML language |
Malformed documents will fail to parse (specifically, the SAX parser used by BFO Publisher will throw a SAXParseException). |
Malformed documents are repaired according to well-defined but opaque rules.
Parse failures are almost impossible but the
repair process
can cause surprises.
For example the CSS rule |
Elements have no namespace unless one is set with the |
An element’s namespace is derived from its name -
so |
Document can interleave any number of different namespaces. Attributes can have namespaces. |
Only HTML, SVG and MathML are recognised officially, and attributes have no namespaces. BFO Publisher has an extension to change this ( see HTML Namespace Extensions). |
The CSS id, class and :lang() selectors match the
|
The CSS id, class and :lang() selectors match the
|
The |
The |
|
As HTML doesn’t support namespaces, |
HTML Namespace Extensions
It is absolutely possible to use BFO Publisher to parse HTML without any additional namespaces, but
some extensions to HTML will require them. In particular the <xi:include> syntax for including
external files requires the appropriate namespace to be defined.
BFO Publisher allows the list of namespaces known to HTML to be customized.
| Name |
bfo-ext-html-namespace |
| Value |
|
The bfo-ext-html-namespace environment variable can configure how namespaces are
derived from HTML input. The values are:
- none
-
no namespaces are derived. Only the HTML, SVG and MathML namespaces can be used. This matches the official HTML specification.
- xmlns
-
the
xmlnsattribute (andxmlns:nnnattributes) get the same meaning they have in in XML, and are used to map both unprefixed or prefixed elements to a particular namespace. - common
-
attributes or elements in a predefined list are recognised as belonging to a specific namespace. This is identical to the list of name=uri option below, except the list is taken from the
HtmlNamespaceExtensionextension to the application (which can be modified). By default, it’s equivant to:xi:include=http://www.w3.org/2001/XInclude /bfo:=http://bfo.com/ns/publisher
This maps the
<xi:include>to the XInclude namespace, and any attributes beginning withbfo:to the BFO Publisher namespace. - auto
-
either the
xmlnsorcommonapproach will be used, depending on which one is encountered first while parsing the document. - list of name=uri
-
a space-separated list of mappings from tags or attributes to a particular namespace. Attributes are prefixed by a slash "/". Children of any elements using this method that have the same prefix will inherit the same namespace. Some examples:
-
include="http://www.w3.org/2001/XInclude"will cause the<include>element in HTML to be mapped to the XInclude namespace -
xi:include="http://www.w3.org/2001/XInclude"will do the same for the<xi:include>element. The prefix before the colon will will be dropped, and the SAX parser will receive an element with a local name ofinclude. -
/bfo:xslt="http://bfo.com/ns/publisher"will map the attributebfo:xslton any element to the BFO publisher namespace. As with the example above, the prefix will be dropped. -
xi:include/bfo:xslt="http://bfo.com/ns/publisher"will map the attributebfo:xslton only thexi:includeelement to the BFO publisher namespace. -
/bfo:="http://bfo.com/ns/publisher"will map any attribute beginning withbfo:on any namespace to the BFO publisher namespace.
-
Once mapped, the additional namespaces can be used in HTML. For example, to use the XInclude syntax:
<html>
<head>
<meta name="bfo-sys-html-namespace" content="xmlns">
</head>
<body>
<xi:include xmlns:xi="http://www.w3.org/2001/XInclude" file="include.html"></xi:include>
</body>
</html>or, using the namespace mapping
<html>
<head>
<meta name="bfo-sys-html-namespace" content="include=http://www.w3.org/2001/XInclude">
</head>
<body>
<include file="include.html"></include>
</body>
</html>Note the use of closing tags is required - although we can customize the namespaces in HTML, we cannot customize the parsing process. Self-closing tags are not part of the HTML syntax, and as the HTML parse is tolerant of unclosed tags a failure to close any custom element like this will result in incorrect output.
Environment variables
BFO Publisher is almost entirely configured with environment variables. These are
not OS environment variables - the term comes from CSS (see https://drafts.csswg.org/css-env/).
In CSS, environment variables look like
env(name), and as with
var(--name) they
can be used anywhere in CSS.
Because their values are fixed and only a few are currently defined, they’re not that useful in normal CSS.
In BFO Publisher however, we make heavy use of them. We define a large number of environment variables
by default, and a user may define custom ones as well. More importantly, as well as being usable in CSS
we use them to configure the file conversion: choosing between PDF or PDF/A output; defining the
current media properties for Media Queries; whether the old or new processing model
for display:run-in
is used; whether the content property applies only to pseudo-nodes (as specified) or to regular
nodes, and many, many more options.
But let’s start with the basics. BFO Publisher sets some variables automatically:
| Name |
bfo-location |
| Value |
always set to the current URL of the file being processed |
| Name |
bfo-format |
| Value |
always set to the shorthand-type of the output being generated - currently "pdf" or "svg" |
And both of these can be used in the CSS, just like any other variable:
<html>
<head>
<style>
@page {
margin: 40mm;
@top-center {
content: env(bfo-location);
}
}
</style>
</head>
<body>
...
</body>
</html>This will automatically add the URL of the file to the page margin.
To set your own environment variable, you can choose from one of several options (note that CSS does not defined a way to set environment variables, so all these methods are unique to BFO Publisher).
-
You can set them using a
<meta>tag in HTML - anynamekeys that are not already defined will set the corresponding environment value. So for example:<html> <head> <meta name="author" content="John Smith"/> <meta name="first-property" content="my-value"/> <meta name="second-property" content="my-value"/> </head> <body> ... </body> </html>This will set the
first-propertyandsecond-propertyenvironment variables, but asauthoris already defined as a meta tag in HTML, it will not set an environment variable. -
You can set them using CSS with the special
@bfo envat-rule:@bfo env { first-property: "my value"; second-property: "my value"; }This is particularly useful because unlike
<meta>, CSS stylesheets can be included with<link>or@import. This lets you create a standard set of environment variables in a CSS file and simply import it into all your documents. -
They can be set when the conversion is started, via the API, command line or through the Web Service.
Configuring BFO Publisher
Almost every configuration that can be applied to a file conversion in BFO Publisher can be configured by setting the appropriate environment variables. Throughout this documentation they’ll be listed just like the two above, in box with "Environment Variable" at the top (for example, bfo-pdf-profile).
Like other at-rules in CSS, they are processed in the normal CSS priority: rules in user stylesheets will override author stylesheets, which will override user-agent stylesheets, and if two rules have the same hierarchy, a later value will override an earlier one.
Most importantly however, environment variables only apply going forward. They will not be applied to any rules already parsed - they’re the CSS equivalent of global constants, so they should be set as near the top of the document as possible. This mostly matters when environment variables are used in Media Queries, see that section for details on how this is done.
PDF Output
The primary output format of BFO Publisher is PDF, which it does by building on the BFO PDF Library, on the market since 2001. So there are a very large number of options that can be set to control exactly how the PDF is created.
PDF/A, PDF/UA and PDF/X
PDF has a number of predefined profiles which impose restrictions on the format in the name of compatibility. Broadly they are:
-
PDF/A (ISO19005) - a subset intended for long-term archiving
-
PDF/X (ISO15930) - a subset intended for blind exchange of documents for print
-
PDF/UA (ISO14289) - a subset intended to improve the experience for accessibility. Think of it as the PDF version of https://www.w3.org/TR/WCAG21/
They all overlap to a degree - it is possible to create a PDF that
is compliant with all three. PDF/A and PDF/X need to be self-describing, so
all fonts and colorspaces are embedded, and PDF/UA requires the PDF to be tagged,
and places restrictions on the HTML input - for example, images need an alt
attribute, tables must be correctly formed with headers etc.
Choosing the profile simply involves setting an environment variable, either
externally or from within the document by way of CSS or <meta> tags.
| Name |
bfo-pdf-profile-base |
| Value |
<profile name> |
| Description |
Adds a named PDF profile to the document profile. May be set more than once |
| Name |
bfo-pdf-profile-require |
| Value |
<feature name> |
| Description |
Sets a named PDF profile feature to required. May be set more than once. |
| Name |
bfo-pdf-profile-deny |
| Value |
<feature name> |
| Description |
Sets a named PDF profile feature to deny. May be set more than once. |
| Name |
bfo-pdf-profile-ignore |
| Value |
<feature name> |
| Description |
Sets a named PDF profile feature to neither require nor deny. May be set more than once. |
| Name |
bfo-pdf-profile |
| Value |
[ <profile name> | <feature name> | -<feature name> ] + |
| Description |
A shortcut property which allows multiple PDF profiles and features to be set at once. Overrides any previous profile settings. Values are separated with spaces, with feature names prefixed with "+" or "-". A plus makes a feature required (or ignored if it was previously denied), and a "-" makes a feature denied (or ignored if it was previously required). |
More than one Profile Name from the following list can be specified, although they must not be incompatible (it cannot be both PDF/A-2 and PDF/A-3, for example). The values are compared lower case and ignoring anything other than letters or digits, so you don’t have to worry about punctuation.
Profile Names
- PDF/A-1b
-
PDF/A-1b is the oldest subset of PDF/A and also the most restrictive, disallowing any form of transparency or compositing. So bitmap images with an alpha channel, the use of CSS
mix-blend-mode,opacityor any colors that aren’t 100% opaque will cause an error. Unless you have a good reason to target PDF/A-1, we do not recommend it. - PDF/A-1a
-
Identical to PDF/A-1b except that the PDF is tagged.
- PDF/A-2u
-
PDF/A-2u restrictions of PDF/A-1. The "u" conformance asserts that all text has a a Unicode value, which BFO Publisher does anyway. PDF/A-2 disallows all file attachments unless they are PDF/A-1 or PDF/A-2 files.
- PDF/A-2b
-
This is PDF/A-2b without the "Unicode text" assertion, so there’s no need to use this profile.
- PDF/A-2a
-
Identical to PDF/A-2u except the PDF is tagged.
- PDF/A-3u
-
PDF/A-3u is identical to PDF/A-2u but allows any files to be attached.
- PDF/A-3b
-
PDF/A-3u without the "Unicode text" assertion, so again there’s no need to use this profile.
- PDF/A-3a
-
Identical to PDF/A-3u except the PDF is tagged.
- PDF/A-4
-
PDF/A-4 that targets PDF 2.0, so allows some of the more modern features of PDF to be used. It disallows all file attachments unless they are PDF/A-1, PDF/A-2 or PDF/A-4 files.
- PDF/A-4f
-
PDF/A-4f is identical to PDF/A-4 but allows any files to be attached.
- PDF/A-4e
-
PDF/A-4e is identical to PDF/A-4f except it allows video, audio and 3D objects to be embedded, which BFO Publisher does with the
<object>,<video>and<audio>tags. - PDF/UA-1
-
PDF/UA-1 is described below.
- PDF/UA-2
-
PDF/UA-2 is described below. When applied, this profile will also apply WTPDF. See below for details) 1.4
- WTPDF
-
WTPDF means "Well Tagged PDF" and can effectively be used as an alias for PDF/UA-2. See below for details 1.4
- PDF/X-1a
-
PDF/X-1 output is described below. PDF/X-1a is very old and not recommended.
- PDF/X-3
-
PDF/X-3 output is described below. PDF/X-3 is very old and not recommended.
- PDF/X-4
-
PDF/X-4 output is described below. It can be combined with PDF/A-2 and PDF/A-3
If that’s all a bit overwhelming, this table should help you choose which PDF/A version to target based on your requirements.
| Profile | Transparency | Multimedia | Attachments | Tags | PDF Version |
|---|---|---|---|---|---|
PDF/A-1b |
- |
- |
- |
- |
1.4 |
PDF/A-1a |
- |
- |
- |
✓ |
1.4 |
PDF/A-2u |
✓ |
- |
strict |
- |
1.7 |
PDF/A-2a |
✓ |
- |
strict |
✓ |
1.7 |
PDF/A-3u |
✓ |
- |
any |
- |
1.7 |
PDF/A-3a |
✓ |
- |
any |
✓ |
1.7 |
PDF/A-4 |
✓ |
- |
strict |
- |
2.0 |
PDF/A-4f |
✓ |
- |
any |
- |
2.0 |
PDF/A-4e |
✓ |
✓ |
any |
- |
2.0 |
Feature Names are the names of an individual PDF profile features in the PDF Library. A predefined profile such as PDF/A-2 is nothing more than set of features that are required or denied. While there will rarely be a need to alter these directly, being able to alter individual features allows the profiles to be customized if required.
| the full list is at https://bfo.com/products/pdf/docs/api/org/faceless/pdf2/OutputProfile.Feature.html |
By way of example, here are two identical ways of creating PDF that complies to both PDF/A-3a and PDF/UA-1a, but is also uncompressed for easy debugging.
<head>
<meta name="bfo-pdf-profile" content="PDF/A-3a PDF/UA-1 -RegularCompression">
</head>
<head>
<meta name="bfo-pdf-profile-base" content="PDF/A-3a">
<meta name="bfo-pdf-profile-base" content="PDF/UA-1">
<meta name="bfo-pdf-profile-deny" content="RegularCompression">
</head>One place you may need to interact directly with profile features is in CSS.
The features, like all environment values, can be extracted in CSS with the env() function,
and these values can be queried in @media rules to allow different rules to apply when a
particular feature is required or denied.
The user-agent stylesheets use this approach to choose which font to embed, or whether to embed PDF 1.x or 2.x tags.
Finally, the PDF/A, PDFX and PDF/UA profiles all introduce the concept of an output-intent to PDF - the color-space of the device the PDF is intended for.
| Name |
bfo-pdf-profile-intent |
| Value |
<url> | <dashed-ident> | device-cmyk | srgb |
| Description |
Sets the indended viewing conditions for the PDF. By default this is sRGB,
but it can be set to whatever the |
Accessible PDFs
HTML and XML documents are structured using tags, but PDF is primarily a page description language so in general has no need for structure. But when consuming a PDF with some form of accessibility technology, such as a screen reader, braille display, or simply removing a background behind text for readabilty, having an XML-like tag structure is crucial.
These accessibilty technologies are commonly abbreviated as "AT", and a PDF with this structure is called a Tagged PDF.
PDF/UA (ISO14289) is a particular profile of Tagged PDF designed to work with AT by placing a number of requirements on on how the tags are used. It comes in two versions:
-
PDF/UA-1 (ISO14289-1:2014) was released in 2014 and targets PDF 1.7, so it’s commonly (but not necessasrily) combined with PDF/A-2a and PDF/A-3a.
-
PDF/UA-2 (ISO14289-2:2024) was released in early 2024, and is considerably more capable than revision one. However it will be a while before tools (and national standards) catch up. It targets PDF 2.0 so would commonly (but not necessarily) be combined with PDF/A-4. 1.4
To further complicate matters, a new standard known as WTPDF is essentially identical to PDF/UA-2 - rather than an ISO standard it was published (for free) by the PDF Association in March 2024. The additional cost of supporting both PDF/UA-2 and WTPDF in a single file is a single entry in the metadata for a cost of about 200 bytes, so BFO Publisher will do this automatically for maximum compatibility: when either of the PDF/UA-2 or WTPDF profiles are requested, both are selected.
Generating a PDF/UA document does not require an in depth knowledge of PDF tags, but it does mean ensuring the source document is created in a certain way. Many of the rules are the same as for HTML documents conforming to WCAG. They’re listed here:
-
The PDF must have a
<title>set (or some equivalent that sets thedc:titlemetadata). -
The PDF must have a valid language set on the root element, eg with
<html lang="NNN">. -
Any
<img>elements must have analtattribute describing the image. -
Any
<figure>elements must have afigcaptionattribute describing the image. -
Any
<svg>elements must have a<desc>element describing the SVG. -
Every
<td>element must map to at least one<th>in the same table (see below for details). -
Fonts must be embedded, as they are for PDF/A.
-
Form fields must have a
<label>or be labeled by way ofaria-labeledbyor similar. Digital signatures must have atitleparameter, which does the same thing. -
Appropriate tags must be used -
<p>for paragraphs,<hn>for headers and so on -
Also be aware that many other requirements for accessibility, such as ensuring suitable contrast between text and background color, are not verified by any PDF/UA checker. These so-called human tests need to be verified by visual inspection; if you’re generating accessible documents, you should be aware of these requirements.
A mapping from a <td> to <th> ensures that every non-header cell in table has a
header describing it. For simple tables, say where the first row or first column is entirely
<th> elements, this can be derived automatically but for more complex tables this may need
to be specified explicitly. As with WCAG, this can be done in one of two ways:
-
A
<th>can havescopeset toroworcolto inform BFO publisher that the header applies to all<td>cells in the same row or column. -
A
<td>can have aheadersattribute set to the ID (or ID’s) of the header cells that describe it.
So long as one of these techniques can be used to map every <td> in a table to a
corresponding <th>, this condition will be met for PDF/UA.
To enable PDF/UA output, use the bfo-pdf-profile tag described in
the previous section
<meta name="bfo-pdf-profile" content="PDF/UA-1" />or use one of the other methods of setting this property
| There is a lot of overlap between PDF/UA and PDF/A, with PDF/UA the more demanding of the two specifications. If you’re going to generate PDF/UA files, consider making them PDF/A compliant as well: with very few exceptions there is zero downside to doing this, and you’ll get an objectively "better" PDF as a result. |
Derivation of HTML from PDF 1.4
BFO Publisher is all about turning HTML into PDF, but there will be occasions when deriving HTML from the generated PDF is necessary. This has always been a difficult task - PDF content is in a fixed position on the page and does not reflow like HTML, so has never needed this sort of layout information to be included.
However the advent of mobile devices and other non-traditional workflows has exposed some of these limitation, and there is a cross-industry working group investigating how best to solve it.
That investigation is ongoing (see https://github.com/pdf-association/Deriving-HTML-from-PDF),
but BFO Publisher is already shipping with an option to aid HTML extraction, in the form
of the Derivation PDF profile. This can be set alone or combined with profiles (ideally PDF 2.0 profiles)
like PDF/UA-2
<meta name="bfo-pdf-profile" content="PDF/UA-2 Derivation" />Exactly what this will do is will change as the specification evolves, but will generally involve:
-
the PDF is tagged, as it would be for PDF/UA.
-
all attributes set on HTML elements are reproduced in the output PDF.
-
local stylesheets are embedded into the PDF in a standard way (defined by the algorithm)
The end result is a bigger file, of course, but how much bigger largely depends on the size of the stylesheets. There are currently very few tools that can parse this information, but the algorithm is a cross-industry effort so we anticipate those tools to emerge in the future.
PDF Declarations 1.4
PDF Declarations were introduced by the PDF Association in 2019 as a
way of claiming adherence to a PDF profile in an easy-to-process many. While typically
these will be set by the profile (see Profile Names), it is also possible to set them
manually using metadata, specifying each declaration in its own <meta> tag:
<meta name="bfo-pdf-declaration" content="http://pdfa.org/declarations#hipaa" />More information on PDF Declarations is at https://pdfa.org/resource/pdf-declarations/
Tagged output
Even without the relatively strict requirements of PDF/UA, Tagged PDF is useful for many PDF consumers.
-
It is more likely to work with reflow tools on devices such as phones
-
It is easier for tools that want to extract data or text from the PDF, such as search engines.
-
It allows metadata and attachments to be applied to sections of the PDF, rather than just the entire file.
While there is a slight cost in terms of file-size and performance, BFO recommend that tags are always enabled unless you’re certain that the generated PDF will never be accessed by anyone using accessibility tools.
Selecting a tagged profile like PDF/A-2a, PDF/A-3a, PDF/UA-1 or PDF/UA-2 will turn on tags automatically, but tags can easily be turned on manually:
| Name |
bfo-pdf-tagged |
| Value |
true | false |
| Description |
Whether to enable PDF tags |
Tagged output will use standard tag mappings from HTML, SVG and MathML. One significant different between PDF 1.x and PDF 2.x is that PDF 2 allows namespaces on the tags. BFO Publisher makes full use of this, and if namespaces are allowed it should be possible to mostly reconsitute the original HTML structure from the PDF.
Customizing PDF Tags and Attributes
To adjust or modify the defauly tag mappings, or to include various optional attributes, we need to wade into the large number of custom CSS properties.
| Name |
-bfo-pdf-tag |
| Value |
|
| Applies to |
any element or pseudo-element that is rendered in the output. |
| Inherited |
no |
| Description |
Sets the PDF "tag" that is applied to this element in the output PDF |
Every element has a mapping defined in the user-agent stylesheet data/tags.css, so the
default value none only applies to unknown elements. The syntax above is a bit dense
and best shown with some examples - note that as PDF 2.x has namespaces and PDF 1.x
does not, you need to choose the syntax that matches your PDF output.
@namespace pdf2 url("http://iso.org/pdf2/ssn");
@namespace mathml url("http://www.w3.org/1998/Math/MathML");
@namespace custom url("http://example.com/ns/custom");
.untagged { -bfo-pdf-tag: none } (1)
span { -bfo-pdf-tag: tag } (2)
li::marker { -bfo-pdf-tag: "Lbl" } (3)
span { -bfo-pdf-tag: tag map-to "Span" } (4)
body { -bfo-pdf-tag: |tag map-to pdf2|"Part" } (5)
mathml|* { -bfo-pdf-tag: |tag } (6)
#myselector { -bfo-pdf-tag: custom|"weird" map-to pdf2|"Div" } (7)
div.heading { -bfo-pdf-tag: "H1" } (8)
div.heading { -bfo-pdf-tag: pdf2|"H1" } (9)| 1 | Any elements with class="untagged" will have no tags in the final PDF - the content of
the element will appear to be be merged with its parent. |
| 2 | (PDF 1.x) Any <span> elements will be written to the PDF using a <span> tag (the value tag
means repeat the original tag. Unless the PDF tag is identical to the source language tag,
this is not the best approach. PDF tags are case sensitive, so the correct tag
would be <Span> |
| 3 | (PDF 1.x) Any ::marker pseudo-elements on a list are mapped to the <Lbl> tag in PDF.
This is one of the default rules taken from the user-agent stylesheet.
As pseudo-elements do not have a tag, the tag value doesn’t apply here. |
| 4 | (PDF 1.x) Any <span> elements will be written to the PDF using a <span> tag,
and then role-mapped to the <Span> tag (note the different case).
This is a standard rule taken from the
user-agent stylesheet - it allows us to keep as much of the HTML semantics as possible
when we write out the PDF, while keeping to the proscribed list of PDF tags.
PDF 1.x role-mapping is quite limited, so we will use it where possible, falling back
to direct use of the role-mapped tag where we can’t. |
| 5 | (PDF 2.x) Any <body> elements will be written as <body> in
the element’s namespace, then role-mapped to Part in the pdf2 namespace
(which is defined earlier in the CSS using the standard @namespace rule).
This is a standard mapping taken from the user-agent stylesheet for PDF 2.x output.
Rolemapping in PDF 2.x is more flexible than in PDF 1.0 and allows us to keep
the namespace URL and use multiple mappings.
Elements should generally be rolemapped to the http://iso.org/pdf2/ssn namespace. |
| 6 | (PDF 2.x) Any elements in the MathML namespace will be written using the same tags and namespace. This is also a standard mapping taken from the user-agent stylesheet: MathML is a standard namespace in PDF 2.x, with the same tags, so this is valid output. |
| 7 | (PDF 2.x) To show the full syntax range for PDF 2.x, this would tag the single element matching
that selector as <weird> in the custom namespace, role-mapping it to <Div>
in the PDF2 namespace. |
| 8 | (PDF 1.x) While it’s rare that the default rules will need overriding, for situations where classes
are used to augment the HTML syntax (for example, using <div class="heading"> instead of <h1>)
then overriding the default tags is a good idea, to ensure the augmented syntax is
reflected in the PDF. |
| 9 | (PDF 2.x) this is the PDF 2.x equivalent of <8> |
Setting -bfo-pdf-tag on an element will tag its content in the PDF, but we still need to determine
what counts as content and what doesn’t: is a background-image part of the element or not?
For this we have the -bfo-pdf-tag-include CSS property.
| Name |
-bfo-pdf-tag-include |
| Value |
|
| Applies to |
any element or pseudo-element with |
| Inherited |
yes |
| Description |
Controls which visible aspects of an element are tagged as part of the tag |
The default value of auto will attempt to do the right thing - it includes borders and content,
but typically not the background of an element as part of its content. For elements where
where the background is semantically significant, setting this property to background will include it.
shadow will include the rasterized box-shadow image. Finally, if-empty will insert the tag
even if it has no content. This is not normally useful, but elements like <td> are usually required
even if empty, to maintain the table structure.
Attributes
The tagged structure in PDF, like the tagged structure in XML, can also make use of attributes.
There are a large number of these described in the PDF Reference - some (like id) are analagous
to XML/HTML attributes, some (like text-decoration-color) are closer to CSS properties.
| Name |
-bfo-pdf-tag-nnn |
| Value |
|
| Applies to |
any element or pseudo-element with |
| Inherited |
no |
| Description |
Sets the value of the attribute nnn on the PDF tag |
In all cases, the universal CSS value unset can be used to disable the attribute, and the
value copy can be used to request the value is derived from the nearest corresponding HTML
or CSS property, if possible. Most attributes default to unset but some default to copy,
as shown below. This distinction is arbitrary - we’ve tried to balance how useful the attribute
is with how verbose the resulting document will be by including it, and there will be many
situations where the context may change this decision.
span.highlight {
background-color: yellow;
-bfo-pdf-background-color: copy; /* it's significant; record it */
}| Custom CSS Property | PDF Attribute | Value |
|---|---|---|
|
the ID for the PDF tag |
<string> (default is copy) |
|
the PDF tag class |
<string>+ (default is copy) |
|
the PDF tag title |
<string> (default is copy) |
|
Layout:Placement |
block inline before start end (default is copy) |
|
Layout:WritingMode |
lr-tb rl-tb tb-rl tb-lr lr-bt rl-bt bt-rl bt-lr |
|
Layout:BackgroundColor |
<color> |
|
Layout:BorderColor |
<color>{1,4} |
|
Layout:BorderStyle |
none hidden dashed solid double groove ridge inset outset {1,4} |
|
Layout:BorderThickness |
<length>{1,4} |
|
Layout:BorderColor |
<length>{1,4} |
|
Layout:Padding |
<length>{1,4} |
|
Layout:SpaceBefore |
<length> |
|
Layout:SpaceAfter |
<length> |
|
Layout:StartIndent |
<length> |
|
Layout:EndIndent |
<length> |
|
Layout:TextIndent |
<length> |
|
Layout:TextAlign |
start center end justify |
|
Layout:Width |
<length> |
|
Layout:Height |
<length> |
|
Layout:BlockAlign |
before middle after justify |
|
Layout:InlineAlign |
start center end |
|
Layout:TBorderStyle |
none hidden dashed solid double groove ridge inset outset |
|
Layout:TPadding |
<length> |
|
Layout:LineHeight |
<length> |
|
Layout:BaselineShift |
<length> |
|
Layout:TextDecorationType |
none underline overline line-through (default is copy) |
|
Layout:TextPosition |
sup sub normal |
|
Layout:TextDecorationColor |
<color> |
|
Layout:TextDecorationThickness |
<length> |
|
Layout:ColumnCount |
<integer> (default is copy) |
|
Layout:ColumnWidths |
<length> |
|
Layout:ColumnGap |
<length> |
|
Layout:GlyphOrientationVertical |
<angle> |
|
Layout:RubyAign |
start center end justify distribute |
|
Layout:RubyPosition |
before after warichu inline distribute |
|
List:ListNumbering |
none unordered description disc circle square ordered decimal upper-roman lower-roman upper-alpha lower-alpha (default is copy) |
|
Table:RowSpan |
<integer> (default is copy) |
|
Table:ColSpan |
<integer> (default is copy) |
|
Table:Headers |
string> (default is copy) |
|
Table:Scope |
string> (default is copy) |
|
Table:Summary |
string> (default is copy) |
|
Table:Short |
<string> |
|
Artifact:Type |
pagination layout page inline |
|
Artifact:Subtype |
header footer watermark pagenum bates linenum redaction <string> |
|
nnn |
<content-list> |
| 1 | The class attribute in PDF may in theory be used to inherit attribute values, but this
approach is not a good fit to the way classes are used in CSS so this approach is not used in PDF |
| 2 | The title of a PDF tag is, roughly, it’s descriptive text. The source for copy will vary depending
on the tag and will often, but not always, be the title attribute of the HTML element |
| 3 | The writing-mode in PDF is problematic, not only because it lists writing modes which are unused in
any known language, but also because in PDF the value influences the order of the values in other properties
such as -bfo-pdf-border-style. It is here for completeness but we very strongly advise against setting it. |
| 4 | -bfo-pdf-tag-border-color and similar attributes can take from 1 to 4 values. In all cases, the values
are specified in the CSS order - clockwise from the top, independent of writing mode. This is not the native
PDF order, but in this context consistency with CSS is more important. We fix it up internally. |
| 5 | Any unrecognised tags will be stored as specified in the PDF - the syntax is described in
https://drafts.csswg.org/css-content-3/#typedef-content-content-list (although the leader() function is excluded).
This would generally be used to copy custom attributes from the source file to the PDF - for example |
<html>
<style>
[data-custom] { -bfo-pdf-tag-custom: attr(data-custom); }
</style>
<body>
<p data-custom="myvalue">Element will have a PDF attribute of "custom" set to "myvalue"</p>
</body>
</html>Pronunciation assistance
Tagged PDF version 2.0 allows a
Pronunciation Lexicon
to be stored in the PDF and phonemes to be associated with a PDF tag. When generating a
Tagged PDF 2.0 file, the data-ssml-phoneme-ph and data-ssml-phoneme-alphabet attributes
defined in https://www.w3.org/TR/spoken-html/#data-ssml-phoneme will be used if specified
(the shorthand data-ssml attribute is also supported).
<link rel="pronunciation"> is an approach taken from the EPUB 3.0 standard.
|
Best practice for pronunciation hints on the internet is far from decided; SSML, ePub and PDF all have enough in common to make support fairly simple. Here’s an example showing SSML attributes specifying the correct pronunciation of the village of Happisburgh, Norfolk, England (which is pronounced Hayes-burra)
<html>
<head>
<meta charset="utf-8">
<meta name="bfo-pdf-profile" content="PDF/A-4"/>
<meta name="bfo-pdf-tagged" content="true"/>
<link rel="pronunciation" href="path/to/norfolk-lexicon.xml"/>
</head>
<body>
<h1>Welcome to <span data-ssml-phoneme-ph="heɪzburrah">Happisburgh</span></h1>
<p>You'll never leave!</p>
</body>
</html>Attachments
It’s possible to
attach
files to a PDF being generated by using a special <link> annotation. Some examples:
<link rel="attachment" href="path/file.pdf"/> (1)
<link rel="attachment/source" href="path/file.html" title="Source HTML"/> (2)
<link rel="attachment" name="file.zip" href="path/nnn" type="application/zip" /> (3)| 1 | The simplest way to add an attachment - just set rel="attachment" |
| 2 | It’s also possible to set the type of attachment, which is a concept
specific to PDF 2.0 and PDF/A-3.
Predefined types are source, data, alternative, supplement, encryptedpayload, formadata, schema or unspecified.
PDF/A-3 requires a type, but we’ll set it to unspecified if it’s missing.
The title attribute can be used to give a description to the link. |
| 3 | You can override the type of the file and use a (non-standard) name attribute to override the file name. |
1.3
If the href attribute is a fragment URL, the element it names will be attached to the PDF as an XML document.
The two exceptions to this are references to <style> and <script> elements: only the content of these element
will be embedded, with a type of text/css for <style>, or the value of the type attribute for <script>
(which has a default value of text/javascript).
Fragment URL processing is new in version 1.3.
Encryption
The generated PDF can be password encrypted, or encrypted with public keys for specific recipients (although this has limited support in PDF viewers). As usual this is controled by environment properties.
| Public-key encryption currently supports RSA end Elliptic Curve keys. |
| all forms of encryption are disallowed in PDF/A. |
For standard password encryption the following properties apply.
| Name |
bfo-pdf-encrypt-password |
| Value |
<string> |
| Description |
The password to open the PDF. If unset and no public-key recipients
are specified, no password will be used. However the PDF will still be encrypted if other
encryption options such as |
| Name |
bfo-pdf-encrypt-admin-password |
| Value |
<string> |
| Description |
The password that’s required to open the PDF and change the encryption. If unset, the encryption cannot be changed. |
| Name |
bfo-pdf-encrypt-cipher |
| Value |
|
| Description |
The cipher and bitlength. AES-256 was introduced with Adobe Acrobat X
and is widely supported, so there’s no reason to use an older one.
It’s the default value if unset.
|
| Name |
bfo-pdf-encrypt-metadata |
| Value |
|
| Description |
Determine if the metadata is encrypted. |
| Name |
bfo-pdf-encrypt-print |
| Value |
|
| Description |
Whether to allow printing. |
| Name |
bfo-pdf-encrypt-change |
| Value |
|
| Description |
Whether to allow changes to the PDF.
|
| Name |
bfo-pdf-encrypt-extract |
| Value |
|
| Description |
Whether to allow text to be extracted for non-accessibility purposes. |
Here’s an example showing a fairly typical use case for password encryption - the PDF can be
opened by anyone with the password password, and once opened it can’t be printed:
| It is up to the application to honour the print, change and extract flags. Do not presume that all will. |
<html>
<head>
<meta name="bfo-pdf-encrypt-password" content="secret">
<meta name="bfo-pdf-print" content="no">
</head>
...
</html>Public key encryption uses a similar set of properties, but instead of bfo-pdf-encrypt-password
and bfo-pdf-encrypt-admin-password there is bfo-pdf-encrypt-recipient.
| Name |
bfo-pdf-encrypt-recipient |
| Value |
<url> |
| Description |
The URL of a public key to use for encryption. |
Each recipient has the print, change and extract rights set at the time the recipient is added - there may be more than one recipient, each with different access rights. The public key is an X.509 certificate which, as with Digital Signatures, can be a KeyStore (the URL may contain fragment parameters to select the key) or a PEM encoded X.509 certificate.
Here’s the above example, changed from password encryption to use a single public key for encryption. Anyone with this key will be able to open the PDF, but won’t be able to print it.
<html>
<head>
<meta name="bfo-pdf-print" content="no">
<meta name="bfo-pdf-encrypt-recipient" content="http://example.com/userx509.cer">
</head>
...
</html>A more complex example allows two students to view the PDF and make no changes, and one
teacher who may edit the form and annotate it. To change things up, let’s assume all the X.509
certificates are in a single file - maybe a Java KeyStore or be a single text file with
multiple PEM encoded certificates, it doesn’t matter.
We’ll use the cn fragment parameter to choose which entry in the key store we want,
just as we can do for Digital Signatures
<html>
<head>
<meta name="bfo-pdf-change" content="no">
<meta name="bfo-pdf-encrypt-recipient" content="http://example.com/keystore#cn=Harry">
<meta name="bfo-pdf-encrypt-recipient" content="http://example.com/keystore#cn=Ron">
<meta name="bfo-pdf-change" content="yes">
<meta name="bfo-pdf-encrypt-recipient" content="http://example.com/keystore#cn=Dumbledore">
</head>
...
</html>General Options
The remaining PDF specific environment variables set general PDF Options - this covers aspects like whether the PDF opens with the bookmarks window or the thumbnail window, whether it opens up in single page or one column mode, and so on.
| Name |
bfo-pdf-nnn |
| Value |
<any> |
| Description |
Any unrecognised property beginning with |
Please consult the API method listed above for the full list. Here’s an example showing how to select the thumbnail panel when the PDF is opened, and display the pages as one long column.
<html>
<head>
<meta name="bfo-pdf-page-mode" content="UseThumbnails">
<meta name="bfo-pdf-page-layout" content="OneColumn">
</head>
</html>Layers
While PDF is usually a static document, the format does have some support for layers. We’re using this term to group two different concepts in PDF - annotations, which sit above the page and are largely independent, and optional content layers which are part of the page, but can be selectively turned on or off.
By default no layers are created, but an element can be assigned to a layer with -bfo-layer-type
and various other -bfo-layer-nnn properties used to configure the layer.
this approach is also used to apply the special rules required to create hyperlinks and
form fields, much like the appearance property has historically been used in browser. We’re not
documenting these aspects.
|
| Name |
-bfo-layer-type |
| Value |
|
| Applies to |
any element that forms a stacking context. |
| Inherited |
no |
| Description |
For values other than |
| Name |
-bfo-layer-name |
| Value |
<string> |
| Applies to |
any element with |
| Inherited |
no |
| Description |
Set the name of the layer. Names should be unique across the documemnt. |
| Name |
-bfo-layer-visibility |
| Value |
|
| Applies to |
any element with |
| Inherited |
no |
| Description |
Controls when this element’s layer should be visible. |
| Name |
-bfo-layer-print |
| Value |
|
| Applies to |
any element with |
| Inherited |
no |
| Description |
Controls when this element’s layer should be printed. |
| Name |
-bfo-layer-export |
| Value |
|
| Applies to |
any element with |
| Inherited |
no |
| Description |
Controls when this element’s layer should be included when the element is exported to a bitmap format ( |
| Name |
-bfo-layer-lock |
| Value |
|
| Applies to |
any element with |
| Inherited |
no |
| Description |
Controls how the layer can be changed after the PDF is created. |
| Name |
-bfo-layer-subject |
| Value |
<string> |
| Applies to |
any element with |
| Inherited |
no |
| Description |
Sets the subject of this annotation layer |
| Name |
-bfo-layer-title |
| Value |
<string> |
| Applies to |
any element with |
| Inherited |
no |
| Description |
Sets the "Content" of this annotation layer - the descriptive text. Required for [PDF/UA] |
| Name |
-bfo-layer-href |
| Value |
<url> |
| Applies to |
any element with |
| Description |
Sets the URL of the file to include. |
| Name |
-bfo-layer-processing-step |
| Value |
<string> which is defined in ISO19593, eg "White", "Braille" or "Structural.Cutting" |
| Applies to |
any element with |
| Inherited |
no |
| Description |
Associates the layer with an ISO 19593 |
Optional Content Layers
Layers are mainly used by tools such as Adobe Illustrator when exporting to PDF, and PDF viewers other than Adobe Acrobat are unlikely to have strong support. Here’s a fairly contrived example that creates three layers, an outer one and two inner ones;
<html>
<style>
.layer {
-bfo-layer-type: layer;
-bfo-layer-name: attr(data-name);
}
.layer[data-hidden] {
-bfo-layer-visibility: hidden;
}
</style>
<div class="layer" data-name="Outer Layer">
Some content
<div class="layer" data-name="en">
An example
</div>
<div class="layer" data-name="es" data-hidden lang="es">
Un ejemplo
</div>
</div>
</html>Open the generated PDF in Adobe Acrobat and you would see the image on the left. Toggle the layers and you would see the image on the right.
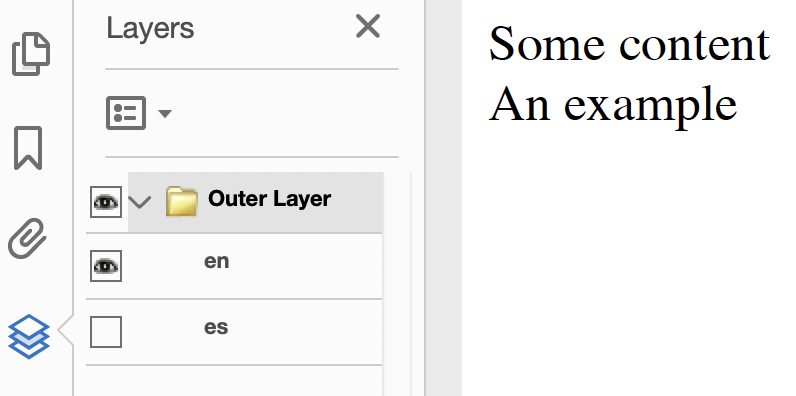
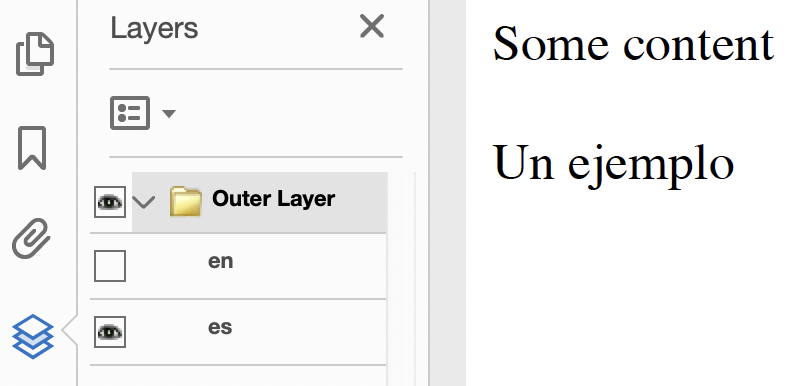
Just because this isn’t a very imaginative demo doesn’t make this feature uninteresting. Using layers with SVG or absolute positioning would allow relatively complex graphics to be displayed in PDF, such as architectural drawings showing different levels. Layer visibility can be set with a hyperlink (see PDF URLs) - help text could be exposed when a user clicks a button, or documents could be toggled between multiple languages.
Optional Content layers like this are valid in PDF/A-2 or later, and they open up some interesting layout possibilities not normally associated with PDF.
Stamp Layers, and other annotations
By changing the -bfo-layer-type to stamp, the elements’s content will be inserted
into a PDF stamp annotation. Annotations in PDF conceptually sit above the page;
the same mechanism is used for text highlights, notes, but also form fields hyperlinks.
As the name implied, they’re intented for stamping content above the page content,
like "Top Secret" or "Draft".
Unlike the optional content layers described previously, stamps cannot be nested -
any use of bfo-layer-type inside a stamp will be ignored - and the stamp annotataion
can be moved, resized or deleted by default in PDF viewers, although this can be
disabled with the -bfo-layer-lock property (not every PDF viewer will respect this).
In the above example, change -bfo-layer-type to stamp in the stylesheet. A single
stamp is created containing all the text, which can be moved, resized or deleted in
most PDF viewers.
Adding bfo-layer-lock: delete will prevent the stamp from being modified, in theory.
In practice at least the macOS PDF viewer does not honour this flag.
For a very different result, changing -bfo-layer-type to note will put the content
(or at least, the text content) into a popup note. This is taking the content
out-of-flow, so the content of the note will not affect layout of surrounding elements
in the same way as if it was absolutely positioned.
Javascript
Any
<script>
elements in the input document normally define scripts to run immediately;
they’re applied to the document itself. However the PDF format also supports JavaScript,
which runs under a completely different environment: there is no DOM, for example, and
instead of dealing with elements there are structures representing pages, form fields
and other PDF constructs.
Currently BFO Publisher does not support JavaScript which is run on the input document,
but scripts which are intended for embedding in the PDF are very much supported. To
mark a script as destined for the PDF, set the type attribute to the value
bfo/pdfscript
<html>
<script>
// Any Javascript here is assumed to be run in the HTML document context;
// BFO Publisher does not support this, so it will be ignored
</script>
<script type="bfo/pdfscript">
// Any Javascript here will be embedded directly into the final PDF.
// If the output format is not PDF, it will be ignored.
</script>
<script type="bfo/pdfscript" src="external.js"></script>
// Any Javascript in "external.js" will be treated as above.
</script>
</html>The use of a custom Media Type will also prevent this content from being processed if the document is loaded in a web-browser.
PDF URLs
BFO Publisher supports some custom hyperlink formats which allow <a> elements
to perform actions within the PDF viewer - although support for these depends on
the viewing environment. Actions such as goto() or FirstPage are fairly widely
supported, but many others will require Adobe Acrobat or a PDF Viewer of a similar level
of suport.
- pdf:show(#fragment)
-
if the PDF has been created with Optional Content Layers, this action will show the specified layer.
- pdf:hide(#fragment)
-
if the PDF has been created with Optional Content Layers, this action will hide the specified layer.
- pdf:toggle(#fragment)
-
if the PDF has been created with Optional Content Layers, this action will show the specified layer if its hidden, and hide it if it’s visible.
<html>
<div id="foo" style="-bfo-layer-type: layer">
Optional Content Layer
</div>
<a href="pdf:show(#foo)">Show layer</a>
<a href="pdf:hide(#foo)">Hide layer</a>
</html>- pdf:submit(url, method)
-
This will submit the PDF "AcroForm" to the specified URL. A detailed discussion of PDF forms is beyond the scope of this document, but as a PDF only has one document-wide form, the process for submitting it is a bit simpler than with HTML.
urlis required, butmethodis optional (it defaults topostif unspecified). Valid values are:-
postto submit the form by HTTP POST -
xmlto submit the form using the XFDF syntax of XML -
xml+annotationsis asxml, but includes the annotations -
pdfsubmits the entire PDF as the value, which includes the current values of the form fields as well as everything else.
-
- pdf:reset
-
This will reset the PDF "AcroForm" fields to their initial values.
- pdf:goto(page, mode)
-
This is an internal hyperlink to a specific page in the PDF. While normally it’s easier to link to an internal element, eg
<a href="#chapter3">, this syntax can be used where a particular page is required.pageis a number starting at 0 for the first page,modeis optional but can befit-width,fit-heightorfitto scale the page to fit the window in the viewer. - pdf:FirstPage, pdf:LastPage, pdf:NextPage, pdf:PrevPage
-
This syntax runs a particular pdf action. The listed four actions are universal, but other actions may be defined for a particular PDF viewer. For example, Adobe define the following values which are supposed to match the correponding actions in Adobe Acrobat:
GeneralPrefs Quit Scan SaveAs Close GeneralInfo Print Spelling Find FindSearch GoToPage GoBack GoForward FirstPage PrevPage NextPage LastPage SinglePage OneColumn TwoPages TwoColumns ZoomTo ActualSize FitPage FitWidth FitHeight FitVisible CollectionPreview CollectionHome CollectionDetails CollectionShowRoot ShowHideArticles ShowHideFileAttachment ShowHideBookmarks ShowHideOptCont ShowHideModelTree ShowHideThumbnails ShowHideSignatures FullScreenMode FindCurrentBookmark BookmarkShowLocation ZoomViewIn ZoomViewOut HandMenuItem ZoomDragMenuItemProbably the most common use will be to print, for example <a href="pdf:Print">Print this file</a>
- pdf:media-NNN(#fragment, …)
-
This syntax is used for control of embedded media, such as video. The syntax is deliberately loose as the current (2022) process for embedding media in PDF is in a state of flux. In general however, the
NNNcomponent of the URL will be action, such asplayorpause, and the first parameter will be the fragment-only URL of the multimedia element to control. Depending on the action, other parameters may be specified.
For example, to play an audio clip embedded in the PDF with the legacy annotation type:
<html>
<audio id="foo" annotation="legacy" src="audio.mp3"/></div>
<a href="pdf:media-play(#foo)">Play Audio</a>
</html>Bookmarks
Bookmarks (also called Outlines in PDF) are a semi-standard part of CSS defined in css-gcpm-3.
| Name |
bookmark-level |
| Value |
|
| Applies to |
any block-level element |
| Inherited |
no |
| Description |
defines the level of the bookmark, with the highest level being 1 (negative and zero
values are invalid). |
| Name |
bookmark-label |
| Value |
<content-list> | |
| Applies to |
any block-level element |
| Inherited |
no |
| Description |
defines the value to display in the bookmark. The |
| Name |
bookmark-state |
| Value |
|
| Inherited |
no |
| Applies to |
any block-level element |
| Description |
the initial state of the bookmark, open or closed. |
| Name |
-bfo-bookmark-target |
| Value |
|
| Inherited |
no |
| Applies to |
any block-level element |
| Description |
values other than auto will cause any generated bookmark to link to the specified url instead of the current element. |
The canonical examples of CSS bookmarks from the specification tend to look like this:
<html>
<style>
h1 { bookmark-level: 1; bookmark-label: content(text); }
h2 { bookmark-level: 2; bookmark-label: content(text); }
/* and so on for h3, h4, h5, and h6 */
</style>
<body>
<h1>Header 1</h1>
<p>Paragraph</p>
<h2>Header 2</h2>
<p>Paragraph</p>
</body>
</html>which presupposes that the depth of each heading is known in advance; the choice of <h1>, <h2>
etc. define the depths. BFO Publisher adds the
copy and increment values for when the depth is not known and the document is structured with nesting.
The example below will have the same bookmark levels as the example above.
<html>
<style>
section { bookmark-level: increment; bookmark-label: none }
.heading { bookmark-level: copy; bookmark-label: content(text) }
</style>
<body>
<section>
<div class="heading">Heading 1</div>
<p>Paragraph</p>
<section>
<div class="heading">Heading 2</div>
<p>Paragraph</p>
</section>
</section>
</body>
</html>SVG Output
BFO Publisher can produce SVG 2 output. Since SVG describes essentially a single image, whereas Publisher is oriented towards paged media with multiple pages, there are several strategies you can use to bridge the paradigm gap between the two.
Essentially there are two independent properties used to control SVG output: encapsulation and pagination.
Encapsulation
Encapsulation describes the strategy used to handle URLs in the SVG output. As a purely Web format, SVG allows specifying arbitrary URLs for links to the resources contained in the document, notably external bitmap images. Arbitrary URLs may also have been specified in the source XML and CSS to load content resources from. However, we usually want the resulting document to be self-contained and not to depend on external content defined elsewhere on the Web, where it may be changed, moved or deleted, or become unavailable due to network failure.
The simplest strategy to overcome this problem is simply to embed all external loaded resources
into the target output SVG. For binary content such as bitmap images, this can be done using a data:
URL.
The advantage of encapsulation is that the resulting SVG has no dependencies and will always look
the same as the source document did at the time that it was processed by BFO Publisher. However,
this comes at a cost. Images and other binary content must be Base64 encoded and embedded into the
output file, which may result in very large files. Also, the data: URL strategy does not support
defining some content once and referencing it in multiple separate places, so there is a potential
for massive duplication of binary assets.
| Name |
bfo-svg-encapsulation |
| Value |
|
The encapsulation configuration parameter specifies the encapsulation strategy.
- all
-
All URLs will be encapsulated. URL references to external bitmap images and fonts will be converted to
data:URLs encoding the resource content. - public
-
URLs in the source will be encapsulated only if they refer to local resources (files and HTTP resources on localhost). Public HTTP resources on external servers will be referenced as-is and trusted to remain unchanged and constant.
- none
-
No URLs in the source will be encapsulated. If there are any references to resources on the local filesystem, they will only be retrievable and displayed if the SVG viewer is run on the same machine with the same permissions.
Pagination
Pagination describes the strategy used to handle paged media in the SVG output.
| Name |
bfo-svg-pagination |
| Value |
|
The pagination configuration parameter specifies the pagination strategy.
- stacked
-
Pagination is essentially ignored. The resulting SVG document will be one image with all the pages stacked on top of one another. This is a good strategy for source documents that were never really intended to be paginated in the first place, such as web pages.
- slideshow
-
Pagination is performed and a separate
<svg>element is created inside the target SVG document for each page. The first "page"<svg>element is marked as "selected" and will be visible in the browser, other pages will not be visible. We include some JavaScript to be able to perform user navigation of the pages via the keyboard or programmatically - it will change which page is selected and thus what CSS display value it has. This strategy is suitable for scenarios where the document is intended to be viewed in a browser by a user. - fragment
-
Pagination is performed and a separate
<svg>element is created inside the target SVG document for each page. The first "page"<svg>element is marked as "selected" and will be visible in the browser, other pages will not be visible. We include some JavaScript to be able to perform user navigation of the pages but this must be done programmatically. - individual
-
One SVG file is created for each page.
Paged Media
An important function of BFO Publisher is its ability to handle CSS paged media instructions and thus format content correctly for paged layout, including page margins, headers and footers, page breaks, and generated content such as page numbers.
Publisher uses absolutely standard CSS syntax to handle pages. However many CSS developers writing for the Web may not be familiar with these instructions, so we’ll explain them a little here.
| The bfo-media-size environment variable can be used to quickly set the default page size. For more control, including setting page margins, a @page rule is required. |
@page rule
The
@page CSS at-rule specifies the overall page layout, including its size and margins.
Other CSS properties can be specified, either for all paged content, or only for pages that match
certain criteria. The @page rule is defined at https://www.w3.org/TR/css-page-3/#at-page-rule
Page selectors can specify a page identifier or page pseudo-classes. The following page selectors are defined:
the
nth() selectors are defined at https://www.w3.org/TR/css-gcpm-3/#document-page-selectors,
which also defines the term page group.
|
:first-
Matches only the first page of the document
:left-
Matches pages that will be on the left hand side if the pages were compiled into a book.
:right-
Matches pages that will be on the right hand side if the pages were compiled into a book.
name-
A named page selector will match a corresponding page attribute on an element - it matches any page in that page group.
:nth(x)-
The
:nth()selector can be used to match a numbered page in the document - the argument x takes the form An + B. Page numbers start at 1 so@page :nth(1)is identical to@page :first,@page :nth(2n)to@page :leftand@page :nth(2n + 1)to@page :right(or the other way around, depending on writing direction). :nth(x of y)-
The
:nth(x of y)syntax matches page numbers the same way as the previous selector, except that matching is done within a named page group rather than in the doucment overall. A page group is established by setting the page property on an element. So@page :nth(1 of body)matches the first page of thebodypage group. :blank-
Matches blank pages that result from a
break-beforeorbreak-aftervalue ofleft,right,rectoorverso. Will not match pages that are incidentally blank.
Whether a page is left or right depends on the writing direction of the document.
If the writing-direction is left-to-right the first page will match :right;
if it has a writing direction of right-to-left it will match :left.
The page property forces the element to be on a page from the named page group, triggering a page
break if necessary.
| Name |
page |
| Value |
|
| Applies to |
any block element |
| Inherited |
no |
| Definition |
Named page groups allow the document to be broken up into sections, allowing different headers or footers to be applied to different sections of the document - for example, a cover page may have no page number, the introduction page numbers in lower-case roman, while the main body of the document uses arabic numerals. Here’s how you could do that:
<html>
<style>
@page introduction {
@top-center {
content: counter(page, lower-roman);
}
}
@page body {
@top-center {
content: counter(page);
}
}
header {
counter-reset: page 1;
page: introduction;
}
main {
counter-reset: page 1;
page: body;
}
</style>
<div id="frontcover"> ... </div>
<header> Introduction here </header>
<main> Main body of document here </main>
</html>This example resets the page counter to 1 to ensure the header and main sections of the PDF both
start at one. The page property causes a new page group to begin, which forces a page break and
allows the :nth(n of m) selector to be applied. For example, to select the second page of the body
section you could use the selector :nth(2 of body).
Be careful:
body:nth(2) means any page which is in the body page group and is page 2 in the document, while
:nth(2 of body) means any page which is the second page in body page group.
|
Page Margin Boxes
Page margin boxes can be used within the @page rule to further subdivide the page into separate regions,
such as headers and footers. These are all CSS at-rules with their own blocks. Conceptually, the page area is
divided into nine boxes. The page content is displayed in the center (horizontally) and middle (vertically).
The corner areas are then referred to as "corners", and the edge areas (above, below, and to either side of the content)
are further subdivided into 3 boxes representing their start, central, and end areas.
The page margin box types are as follows:
@top-left-corner-
Specifies rules applied for the top left corner area.
@top-left-
Specifies rules applied for the top left area.
@top-center-
Specifies rules applied for the top center area.
@top-right-
Specifies rules applied for the top right area.
@top-right-corner-
Specifies rules applied for the top right corner area.
@left-top-
Specifies rules applied for the left top area.
@left-middle-
Specifies rules applied for the left middle area.
@left-bottom-
Specifies rules applied for the left bottom area.
@right-top-
Specifies rules applied for the right top area.
@right-middle-
Specifies rules applied for the right middle area.
@right-bottom-
Specifies rules applied for the right bottom area.
@bottom-left-corner-
Specifies rules applied for the bottom left corner area.
@bottom-left-
Specifies rules applied for the bottom left area.
@bottom-center-
Specifies rules applied for the bottom center area.
@bottom-right-
Specifies rules applied for the bottom right area.
@bottom-right-corner-
Specifies rules applied for the bottom right corner area.
| Name |
size |
| Value |
|
| Applies to |
the |
| Definition |
The size property specifies the target size and orientation of
the page box.
It is only relevant inside an @page block. In PDF terminology it sets the trim box (unless the bleed
property is negative, in which case it sets the bleed box).
- auto
-
Default values are used. In BFO publisher this means the size is taken from the media size, which is set with the bfo-media-size environment variable. See Media Queries.
- landscape
-
The page content is displayed in landscape mode: the longest side is horizontal.
- portrait
-
The page content is displayed in portrait mode: the longest side is vertical. This is the default.
- <length>
-
The first value specifies the width of the page and the second its height. If only one value is provided, it specifies both width and height.
- <page-size>
-
This a keyword representing one of the pre-defined page sizes:
A3,A4,A5,B4,B5,JIS-B4,JIS-B5,letter,legal, orledger.
New sizes are added with an environment variable, e.g. set bfo-sys-page-size-a6 to 105mm 148mm
|
| Name |
marks |
| Value |
|
| Applies to |
the |
| Definition |
| Name |
bleed |
| Value |
|
| Applies to |
the |
| Definition |
The marks property determines whether printer marks are added to the page. With the bleed property,
printer marks show the printer where to trim the output.
The bleed property specifies the extent of the page bleed area outside the page box defined by size.
Bleed is typically set when the page contains backgrounds that are supposed to extend to the edge.
Any solid, gradients, or tiled image backgrounds that extend to the edge of the area defined by size will
be automatically extended into the bleed box.
When specified as a positive length it determines how far outward, in each direction, the bleed box extends
past the page box. If specified as a negative length then the size property is assumed to specify the bleed box,
and the bleed property defines the trim box with respect to that.
The default value of auto evaluates to 0 unless the page has crop marks (see the marks
CSS property), in which case it’s 6pt.
| Name |
-bfo-trim |
| Value |
|
| Applies to |
the |
The -bfo-trim property specifies the distance between the page box (i.e. the box defined by the size
property) and the edge of the physical page, known as the media box in PDF. As with bleed, the
default value of auto evaluates to 0 unless the page has crop marks, in which case it’s bleed + 6pt.
This property is a shorthand for the properties
-bfo-trim-top, -bfo-trim-right, -bfo-trim-bottom, and -bfo-trim-left,
which define the distances for each individual side in the same way as padding or margin.
It’s also possible to specify a value like -bfo-trim: to A4, which would set the four trim sizes to
expand the page to a media box of A4, centering the content. This syntax is the word to followed by
any value that would be valid for the size property (so to auto is valid).
A diagram may help to visualize this.

Here are some more example @page rules. Note the default page margin is 0, so
if you’re setting any margin content, you should set margin too.
@page {
size: A4;
margin: 2cm;
}@page {
size: letter;
margin: 0.5in;
@bottom-center {
content: "Page " counter(page) " of " counter(pages);
}
}
@page :first {
margin-left: 1.5in;
}If you’d prefer to set the media box of the page directly and derive the trim box from that,
that’s possible with some custom properties and calc() functions:
:root {
--media-width: 210mm;
--media-height: 297mm;
--trim-top: 25mm;
--trim-right: 25mm;
--trim-bottom: 25mm;
--trim-left: 25mm;
}
@page {
-bfo-trim: var(--trim-top) var(--trim-right) var(--trim-bottom) var(--trim-left);
size: calc(var(--media-width) - var(--trim-left) - var(--trim-right))
calc(var(--media-height) - var(--trim-top) - var(--trim-bottom));
}Page breaks
An important function of pagination is controlling where page breaking occurs. Page breaks are controlled via the following CSS properties:
| Name |
break-before |
| Value |
|
| Applies to |
block-level boxes, grid items, flex items, table row groups, table rows |
| Inherited |
no |
| Definition |
| Name |
break-after |
| Value |
|
| Applies to |
block-level boxes, grid items, flex items, table row groups, table rows |
| Inherited |
no |
| Definition |
| Name |
break-inside |
| Value |
|
| Applies to |
all elements except inline-level boxes, internal ruby boxes, table column boxes, table column group boxes, absolutely-positioned boxes |
| Inherited |
no |
| Definition |
The break-before, break-after, and break-inside property specifies how page breaks should occur
before, after, and inside a box respectively.
- auto
-
Allows (but does not force) a break.
- always
-
Forces a break.
- avoid
-
Avoids a break if possible.
- left
-
Forces one or two breaks, such as to place the box after the break on a "left" page.
- right
-
Forces one or two breaks, such as to place the box after the break on a "right" page.
- recto
-
Forces one or two breaks, such as to place the box after the break on a recto page.
- verso
-
Forces one or two breaks, such as to place the box after the break on a verso page.
- page
-
Forces a page break.
- avoid-page
-
Avoids a page break if possible.
Note that where page breaks occur is part of CSS fragmentation more generally; thus, some property values are agnostic as to whether they are page breaks or column breaks in multi-column output, whereas some are specifically relevant to page breaks.
Additionally, there are two properties that can be used to avoid breaking inside paragraphs that would result in too few lines in the paragraph before or after the break.
| Name |
orphans |
| Value |
<integer> |
| Applies to |
block containers that establish an inline formatting context |
| Inherited |
no |
| Definition |
The orphans property specifies the minimum number of lines in a block container that must be shown
at the bottom of the page. It must be a positive integer; the default value is 2.
| Name |
widows |
| Value |
<integer> |
| Applies to |
block containers that establish an inline formatting context |
| Inherited |
no |
| Definition |
The widows property specifies the minimum number of lines in a block container that must be shown
at the top of the page. It must be a positive integer; the default value is 2.
Media Queries
BFO Publisher fully supports
media queries
as defined in https://www.w3.org/TR/mediaqueries-4/,
plus a few useful extensions. The default media type is considered to be print to an A4 page size,
but as all media properties can be overriden with environment variables this is easy to change.
Pre-defined environment variables correspond to each non-derived media feature defined
in https://www.w3.org/TR/mediaqueries-4/: width matches bfo-media-width, resolution matches
bfo-media-resolution and so on. Most of these will never need changing, but some that will be are
listed here.
| Name |
bfo-media |
| Value |
|
| Description |
Set the type of media query that matches in a Media Query |
| Name |
bfo-media-size |
| Value |
|
| Description |
A shortcut property that sets |
| Name |
bfo-media-monochrome |
| Value |
|
| Description |
Determines whether the output device is considered to be monochrome or not. The default of 0 indicates a color device. |
Media Queries and environment variables
BFO Publisher also accepts a non-standard syntax that allows environment variables to be used in Media Queries. This can be used to match a Media Query against any environment variables in use for the document:
@media (env(bfo-format): pdf) {
/* This block evalutes if the "bfo-format" environment variable is set to "pdf" */
:root {
key: value;
}
}As BFO Publisher output is entirely controlled by environment variables, this is extremely
useful. For example the bfo-format variable is always set to the output format being
generated; in the example above, the rule will only be applied for PDF output, not SVG output.
For PDF output, environment variables are set for each OutputProfile Feature that is required or denied. This terminology comes from the PDF Library, and it’s how we make the distinction between regular PDF output and PDF/A, PDF/X, PDF/UA and on.
For example, when generating tagged PDF output for PDF/UA, we need to make a distinction between tags suitable for PDF/UA-1 (based on PDF 1.x) and PDF/UA-2 (based on PDF 2.x). One of our user-agent stylesheets does this with a rule like this one:
@media (env(bfo-pdf-profile-feature-PDFVersion20): deny) {
/* Rules for PDF 1.x are set here */
}
@media (env(bfo-pdf-profile-feature-PDFVersion20): require) {
/* Rules for PDF 2.x are set here */
}We can use the same approach to select different fonts for serif and sans-serif,
choosing between unembedded or embedded versions depending on what is allowed with the
standard PDF output. For a full list of features refer to the
PDF Library API Documentation,
and for some examples see the data/tags.css stylesheet in the Jar.
Finally, as this syntax is unique to BFO Publisher it can be used to create rules that are only applied in this user-agent, and will never be applied when rendering in browsers but also other CSS to PDF output engines.
@media (env(bfo-format)) {
/* Rules here will only ever be applied in BFO Publisher */
}Counters and generated content
CSS has a fairly sophisticated method of generating content - text which is inserted into the document but is not part of the input DOM. Typical uses are list counters, but any number of custom counters can be specified. BFO Publisher has full support for all types of generated content in the specification.
Unfortunately the specifications governing this are scattered: CSS Content 3, CSS Lists 3 (for counters) CSS Page 3 (for counters as the apply to pages) and CSS GCPM 3; although the latter is quite ancient, it has been used as a basis by most print layout engines.
Page counters
The user-agent stylesheet defines the follow standard rules
:root {
counter-reset: page 0;
}
@page {
counter-increment: page;
}Together they define a page counter which will increment every time a new page is created (the first page
is created after the root box - https://github.com/w3c/csswg-drafts/issues/4759 - so has the value 1).
page is like any other counter - it can be reset or
have its increment altered at any point. For example, it might be useful to have the header of the document
use roman numerals and then reset the counter to 1 for the main body of the document
@page header {
@top-center {
content: counter(page, lower-roman);
}
}
@page main {
@top-center {
content: counter(page, decimal);
}
}
#header {
page: header;
counter-reset: page 1;
}
#main {
page: main;
counter-reset: page 1;
}Other page-based counters can be used too - to ensure they’re in scope (see https://www.w3.org/TR/css-lists-3/#nested-counters)
just be sure to add a counter-reset: page 0 your-custom-counter 0 rule to the :root element.
All counter formats described in https://www.w3.org/TR/css-counter-styles-3/ are supported, as is the
@counter-style
rule. BFO Publisher supports one additional counter-style
which is particularly useful for page-based counters: auto, which means
use whichever format was most recently used for formatting this counter.
This value is particularly useful for target-counter(),
where we’ve made it the default format (the specification says it should
be decimal). target-counter() is used to reference the value of a counter in another
element, typically (but not necessarily) the page number.
A default value of auto means that the formatting used in the target element will be used.
In the example above, using target-counter(url(#header), page) will get the page
counter from the node with id="header", and format it using whatever format was most recently used at that point
(which is lower-roman, as that’s the format in the margins for that page).
target-counter(url(#main), page) will get a counter format of decimal instead.
BFO Publisher also defines three special additional counters which cannot be altered by counter-increment or counter-reset.
-
-bfo-page-close- the value of thepagecounter at the close of the element. -
-bfo-page-physical- the physical page in the document, with the first page starting at 1 -
-bfo-page-physical-close- the value of the-bfo-page-physicalcounter at the close of the element.
These three counters exist mostly for Index Generation, but could be used in the document itself. For example, if a section ran over several pages it’s possible to list them all as a range.
<style>
.pageref[href='^#']::after {
content: target-counter(attr(href url), page) "-" target-counter(attr(href url), -bfo-page-close);
}
</style>
<table id="bigtable>
... many pages of table ...
</table>
...
<p>
See the tables on <a class="pageref" href="#bigtable">pages </a> <!-- eg output is "pages 54-95" -->
</p>PDF viewers (such as Adobe Acrobat) also need to display the current page external to the document,
for example in the page dialogs. This value is known as the page label. This is controlled with the
-bfo-page-label property
| Name |
-bfo-page-label |
| Value |
|
| Applies to |
the @page descriptor |
| Description |
sets how the page number is formatted in the user-interface of a PDF viewer |
The -bfo-page-label value determines how the page is formatted in external PDF viewers. The default
value of normal will set the page label to match the page counter, as it’s displayed in the margins.
So for example, if the page is displayed formatted as lower-roman, the value will be stored as
lower-roman. If the page number is not displayed anywhere in the margins of the current page, the
formatting from the last preceding page containing the page is used, or (if no preceding page contains
the page number), the page is formatted as decimal.
A value of none removed any special formatting, which causes the page number to be formatted as decimal.
Other strings are theoretically possible, but the PDF viewer may not honour the value.
The default value normal is likely to be required for compliance with PDF/UA-2
Lookahead mode
Layout begins with the first page and ends with the last, which leads to a problem when using the pages
counter, or the target-counter for an element that hasn’t yet been laid-out. How do we know what the
value will be if it hasn’t been computed yet?
There are two approaches to work around this. First, we can allocate a fixed amount of space on the page for the counter, then come back and fill it in when the document is complete. Or, we can do a trial layout of the document to establish the value of the counter.
Which approach is controlled with the bfo-lookahead environment property
| Name |
bfo-lookahead |
| Value |
|
| Description |
determines whether BFO Publisher should do a trial layout pass if required. |
The default value is true, which means whenever a future value is required, the layout will
continue until that value is known, then repeated with the correct value inserted into the DOM. This gives
the best results but can require two passes - if the pages counter is used, we have to continue until
the end of the document. BFO Publisher will avoid this where possible - for example, an entry in a
table-of-contents preceded by a leader() does not require two passes, as the leader can be resized.
The alternative is to allocate a fixed block of space on the page for the number. This allows rendering
to run in a single pass, which will be a significant win for documents with thousands of pages. The
size of the gap is unlikely to be correct, but careful layout can minimise the effect of this - for example,
ensuring there is no content to the right of a pages counter and that it’s left or center aligned on
the page means the gap will not be noticed.
XInclude
BFO Publisher supports the
xi:include
element as defined
at https://www.w3.org/TR/xinclude/,
as well as all the semi-official extensions from the 1.1 working
group note at https://www.w3.org/TR/xinclude-11/.
XInclude is fairly well established in XML, although has not been adopted into HTML. BFO Publisher allows it to be used with either syntax (see HTML Namespace Extensions). It’s typically used to embed XML content into a larger document, but can include plain text as well.
<html xmlns="http://www.w3.org/1999/xhtml" xmlns:xi="http://www.w3.org/2001/XInclude">
<body>
<xi:include href="chapter1.xml" />
<xi:include href="chapter2.xml" />
</body>
</html>The XML resource will be included exactly as if it were part of the source document. Resources can be included more than once, and can themselves include further documents to make a tree of content. Loops will be safely detected and ignored, and in all cases the content will be streamed rather than imported into memory - important, as it’s possible to make very large documents this way.
BFO Publisher includes HTML content by converting it to XML, although
the HTML parsing rules mean the included content will always be wrapped
in an <html> and <body> element if they are missing from the source files.
As well as the enhancements and attributes defined in the 1.1 working note, we’ve added a few enhancements of our own to the syntax.
-
The
<xi:include>element can take an optionalbfo:xsltattribute, which defines one (or more) XSLT stylesheets to apply to the included content (see XSLT). -
Any other namespaced attributes (excluding
bfo:xslt) will be inherited by the included element (or elements), as specified in XInclude 1.1. This includes thebfo:scopeattribute which will cause the included elements to act as scoping roots (see Style Scoping). -
BFO Publisher supports the use of any Media Type in the
parseattribute as specified in XInclude 1.1, and defaults to the native Media Type of the resource (note that this is a departure from the specification, which requires a default type ofxml. In almost all cases the effect is the same).text/htmlcontent will be converted to XML, and types other thentext/plain,text/htmlor an XML type will include the object as an attachment. -
the XInclude specification disallows the URL fragments, requiring a
fragidattribute instead. We don’t understand the problem this is trying to solve; BFO Publisher allows both by default, with the fragid taking precedence. -
The
xpointerattribute is supported, although the more powerfulbfo:xsltattribute is a better choice for complex work. Schemesxpathandelementare supported as well as a bare word matching an element id (note XPath comes as part of XSLT, so requires an implementation in the classpath). When combined with thebfo:xsltattribute the XSLT transformation is applied first, then the xpointer used to select an element from the transformed result. But as XSLT can do everything XPointer can, mixing the two is neither necessary nor advised.A particularly useful xpointer example is including only children of the element being included.
<!-- main file --> <html xmlns="http://www.w3.org/1999/xhtml" xmlns:xi="http://www.w3.org/2001/XInclude"> <body> <table> <xi:include href="subtable1.xml" xpointer="xpath(/*/*)" /> </table> </body> </html> <!-- subtable1.xml --> <ignored-outer-element xmlns="http://www.w3.org/1999/xhtml"> <tr><td>...</td></tr> <tr><td>...</td></tr> <tr><td>...</td></tr> </ignored-outer-element> -
Don’t forget to namespace the included elements! The above example shows how to do it - the included elements will not inherit the namespaces of the parent context: if you forget to specify the namespace, the content is unlikely to be styled correctly.
Resources within an included document are resolved against the URL of the
included resource, as specified.
This leads to a potential ambiguity when the links are fragment links only, for
example <a href="#toc">Contents</a>. We resolve this by first searching the included
document for that fragment, falling back to a wider search of the whole document if not found.
This ambiguity can be avoided by specifying the path:
if document.xht included chapter.xht, a link within either of those files to
chapter.xht#heading or document.xht#heading is unambiguous. Relative links to an
element in a resource included more than once will refer to the first instance.
Style Scoping
When including XML or HTML the content becomes part of the parent document so will inherit
the styles from its container, and any styles defined in the included file will also apply globally.
As this behaviour isn’t always desired, BFO Publisher defines a bfo:scope property to control
this - while it can be used anywhere, it’s most useful with xi:include.
| Name |
bfo:scope |
| Value |
|
| Applies to |
the value |
The values have the following meanings:
- normal
-
No special scoping rules. This is the default.
- inherit
-
Any element with
bfo:scope="inherit"will act as a Scoping Root. Any stylesheets defined within this element will be discarded when the element is closed. Any stylesheets applied outside this element will continue to apply to the element and its descendants. - isolate
-
The same as
inherit, except that stylesheets applied outside this element will not apply to the element and its descendants. The subtree is isolated from the rest of the document. - all
-
When
bfo:scope="all"is set on a<style>or<link>element, any styles rules defined by that element will be applied even to elements that have setbfo:scope="isolate". The ability to "punch through" this isolation is useful for style rules like@font-facewhich are intended for all content in the document regardless of isolation.
Here are some examples showing how this works. For clarity we’ve set bfo:scope on inline elements,
which is perfectly valid, but we’d expect this to be mostly used on <xi:include>
<html xmlns="http://www.w3.org/1999/xhtml" xmlns:bfo="http://bfo.com/ns/publisher">
<style>
p { font-weight: bold }
</style>
<body>
<div id="d1" bfo:scope="inherit">
<style>
p { font-style: italic }
</style>
<p id="p1">This text is bold and italic</p>
</div>
<p id="p2">This text is bold only</p>
</body>
</html>In this example, the paragraph p1 has the bold style from the first stylesheet, and the italic
style from the second stylesheet. When the div d1 closes, the bfo:scope="inherit" means the
inner stylesheet is discarded, and paragraph p2 is no longer italic.
<html xmlns="http://www.w3.org/1999/xhtml" xmlns:bfo="http://bfo.com/ns/publisher">
<style>
p { font-weight: bold }
</style>
<body>
<div id="d1" bfo:scope="isolate">
<style>
p { font-style: italic }
</style>
<p id="p1">This text is italic only</p>
</div>
<p id="p2">This text is bold only</p>
</body>
</html>In this example, the paragraph p1 is only styled with the second stylesheet:
the bfo:scope="isolate" prevents stylesheets defined outside
the div d1 from applying within it.
As with the previous example, the second stylesheet is discarded when d1 is closed.
<html xmlns="http://www.w3.org/1999/xhtml" xmlns:bfo="http://bfo.com/ns/publisher">
<link rel="stylesheet" href="myfont.css" bfo:scope="all" />
<style>
p { font-weight: bold; font-family: MyFont }
</style>
<body>
<div id="d1" bfo:scope="isolate">
<style>
p { font-style: italic; font-family: MyFont }
</style>
<p id="p1">This text is italic "MyFont"</p>
</div>
<p id="p2">This text is bold "MyFont"</p>
</body>
</html>Sometimes style rules should cross into isolated scopes - for example,
when they define resources like fonts.
The addition of bfo:scope="all" to the stylesheet at myfont.css will
ensure that any rules it defines (such as @font-face) are applied
even to isolated scopes.
The bfo:scope attribute can be set on any element. When set on <xi:include>,
as with any namespace-qualified attribute it will be propagated to the root element
(or elements, if appropriate) of the included resource.
Elements which set bfo:scope to isolate or inherit will match the :scope
CSS selector (if no scope is declared, the :scope selector matches the root element).
The :scope selector and the concept of a scoping root are
standard CSS concepts,
but the creation of a scope is not currently defined in CSS or HTML.
HTML used to define a scoped attribute with similar functionality,
but this was deprecated in
2014 and eventualy removed from implementations. The concept
remains popular
amongst developers, and we’ve implemented this in Publisher due to the
many advantages it brings
to managing styles for large documents comprised of many included sections.
|
XSLT
BFO Publisher supports using XSLT to transform the source XML before processing. There are two ways this can be applied.
First, the
<?xml-stylesheet?>
processing-instruction,
as specified in https://www.w3.org/TR/xml-stylesheet/.
For example:
<?xml-stylesheet href="transform.xslt"?>
<?xml-stylesheet href="stylesheet.css"?>
<document xmlns="http://mycompany.com/myschema">
<widget>
<data>Content>
...The XML will be transformed by the transform.xslt stylesheet before it
is processed by BFO Publisher - in the above example, a CSS stylesheet
will also be applied to the transformed XML.
It is possible to specify multiple XSLT stylesheets with this approach,
and they will be applied in the order they’re specified.
Any relative URLs will be resolved against the original URL of the
Document, ignoring any HTML <base> element or xml:base attributes
in the source.
For a more flexible alternative unique to BFO Publisher,
any element in the XML can have a bfo:xslt attribute specified on it.
| Name |
bfo:xslt |
| Value |
<url> [ <url>* ] |
| Applies to |
all elements, with special processing when set on |
This attribute contains be the URL of one or more XSLT stylesheets;
multiple URLs are separated with spaces.
Unlike <?xml-stylesheet?> the stylesheets will be applied to the
subtree it’s specified on.
This is particularly useful for transforming content included from another
file with the <xi:include> element (see XInclude).
If set on <link> and the link element’s rel attribute includes attachment,
the target of the link element will be transformed by the specified stylesheet(s) before
it’s attached to the PDF. See Attachments 1.3
<aside id="fxrate">
<h2>Exchange rates</h2>
<p>Values current as of today</p>
<xi:include href="http://fx.example.com/feed.xml" bfo:xslt="fx-to-html.xslt" />
</aside>The processing is done by the XsltAttributeExtension extension,
one of the default set of extensions used by BFO Publisher.
It uses the standard javax.xml.transform package to transform the XML.
| XSLT is not included in Java SE, so requires an implementation to be added to the classpath. We highly recommend Saxon, and have also tested with Apache Xalan. BFO Publisher will correctly stream events when used with XSLT 3.0 streaming stylesheets and if the XSLT engine that supports them - currently this is only Saxon EE. |
Finally, a Java class can be specified to transform the XML instead of XSLT. This is useful for very specific transformations that would be difficult with XSLT, and as BFO Publisher supports multiple transformations it can be applied alongside an XSLT transformation if necessary. The index in the PDF version of this document is created using this approach.
Use a classpath URL to specify the class that will perform the transformation:
the class must implement both org.xml.sax.XMLFilter and org.xml.sax.ContentHandler,
have a public no-argument constructor, and it must already be in the Java classpath.
<div id="index">
<xi:include bfo:xslt="classpath:com.example.MyXMLFilter file:/path/to/finaltranform.xsl"
href="about:index"/>
<div>The XML will be processed by the com.example.MyXMLFilter class,
with the output further transformed by the /path/to/finaltransform.xsl
XSLT stylesheet before being included in the final document.
Here’s an example XMLFilter that converts all element names to lower case:
package com.example;
public class MyFilter extends XMLFilterImpl {
@Override
public void startElement(String ns, String l, String q, Attributes atts) throws SAXException {
lname = lname.toLowerCase();
super.startElement(ns, lname, qname, atts);
}
@Override
public void endElement(String ns, String l, String q) throws SAXException {
lname = lname.toLowerCase();
super.endElement(ns, lname, qname);
}
}Linking Resources
The HTML <link> element is the standard way to link to resources in HTML, and is fully supported
in BFO Publisher. What is less well known is that a document-wide link header can also be
specified with HTTP Headers.
RFC8288 specifies how the Link HTTP header can be
used instead of <link> - the two syntaxes are virtually identical
(mozilla.org have a good writeup)
and this is supported by BFO Publisher - although it does require that the document XML/HTML is
served over HTTP.
Another approach unique to BFO Publisher is the use of a link processing instruction. The syntax looks like this:
<?link rel="attachment" href="path/to/file.xml" ...?>
<html xmlns="http://www.w3.org/1999/xhtml">
...
</html>Anything you can do with a <link> element in the document head, you can also do with this processing
instruction. The approach is useful when the input document is being processed somehow (say with
FreeMarker or XSLT), and as processing instructions can be added programattically to any
input via the API or with the Web Service, it adds quite a lot of flexibility: the link instruction
no longer has to be part of the input document. See the [Factur-X] section for an example of where
this is particularly useful
FreeMarker and ZTemplate Templates 1.3
BFO Publisher supports using Apache FreeMarker (https://freemarker.apache.org) or ZPath ZTemplates (as specified at https://zpath.me) as a template pre-processor. Of course either of these or any other template processor can always be run manually to generate the input HTML or XML prior to processing it with BFO Publisher, however there are some advantages to doing the Template processing in BFO Publisher.
-
Ease of use - the template processing (which occurs in FreeMarker or ZTemplate) and the subsequent conversion of the output to PDF (in BFO Publisher) is presented as a single step
-
Templates can be processed via the WebService interface.
-
Where possible, templates conversion is streamed into the next stage rather than storing the content in memory.
FreeMarker is invoked by adding a freemarker processing instruction to the file being
parsed, exactly the same way as for XSLT processing. If the data is stored in XML this
is trivial: the example from the
FreeMarker documentation
could be represented like so
<?freemarker href="path/to/template.ftl"?>
<data>
<user>Big Joe</user>
<latestProduct>
<url>products/greenmouse.html</user>
<name>green mouse</user>
</latestProduct>
</data>ZTemplates works exactly the same way, except a ztemplate processing instruction is used.
<?ztemplate type="text/html" href="test.ztl"?>
<data header="Colors">
<items>
<item first="true"><name>red</name><url>#Red</url></item>
<item link="true"><name>green</name><url>#Green</url></item>
<item link="true"><name>blue</name><url>#Blue</url></item>
</items>
</data>XML requires a single, named root element - we’ve used <data> for this, and if using FreeMarker
the template would reflect that.
XML is a useful example as it allows us to draw parallels with XSLT, but a more typical serialization format for input to a modern Template language would be JSON or CBOR, both of which can be processed the same way. As processing-instructions cannot be added to JSON, one needs to be added manually via the API.
Report report = reportFactory.createReport();
ProcessingInstruction pi =
new ProcessingInstruction("ztemplate", "href=\"path/to/template.ztl\"");
report.getProcessingInstructions().add(pi);
report.load(new File("data.json"));
report.parse();
PDF pdf = output.getPDF();
pdf.render(new FileOutputStream("out.pdf"));For FreeMarker, it’s identical except for the change to the processing instruction
ProcessingInstruction pi =
new ProcessingInstruction("freemarker", "href=\"path/to/template.ftl\"");
// or, if you prefer
ProcessingInstruction pi = new ProcessingInstruction()
.setType("freemarker")
.put("href", "path/to/template.ftl");The same example from the FreeMarker documentation we referred to above could be represented in JSON as
{
"user": "Big Joe",
"latestProduct": {
"url": "products/greemouse.html",
"name": "green mouse"
}
}Finally, this approach can also be used to a Template to a FreeMarker TemplateModel which can
be created from a HashMap or similar. Just pass the TemplateModel into the report.load() method.
For ZTemplate, the engine we’re using is https://github.com/faceless2/zpath - this can accept
a com.bfo.json.Json or java.util.Map as input directly, so just pass that into report.load().
HTML, XML and relative paths
The output from any Template is assumed to be HTML by default; this is the case even if the data
was originally loaded from an XML file. If the Template generates XML instead then
this must be specified by adding a output-type="text/xml" attribute to the processing instruction.
Our first example above would now look like this:
<?freemarker output-type="text/xml" href="path/to/template.ftl"?>
<data>
...or when using the API
ProcessingInstruction pi =
new ProcessingInstruction("freemarker", "output-type=\"text/xml\" href=\"path/to/template.ftl\"");
// or, if you prefer
ProcessingInstruction pi = new ProcessingInstruction()
.setType("freemarker")
.put("output-type", "text/xml")
.put("href", "path/to/template.ftl");If the Template contains relative URLs to images or other resources, they will be resolved relative to the path of the Template file, not relative to the data file being parsed.
Configuration and Security
Environment variables beginning with freemarker. are passed to the FreeMarker configuration,
minus the freemarker. prefix. For example, setting the Environment variable
freemarker.incompatible_improvements to 2.3.27 would configure FreeMarker to use that version of its API.
The bfo-lang environment variable, used to set the default language of the Report,
is also used to set the FreeMarker default language.
FreeMarker supports recursion, so a malicious template could use all the available memory in Java.
BFO Publisher will resolve
the URL in the processing-instruction as normal, so in theory Templates could be loaded from any URL.
To mitigate the security implications here, we’ve added a concept of a trusted resource. URLs
with a scheme of file, jar or classpath are trusted, and so can contain a Templates.
Attempting to load a Template from a non-trusted URL will fail.
This is mostly of interest when using the web-service.
ZTemplate is a much simpler template language, and the only configurable is bfo-lang
is used to set the default locale for templates, as with FreeMarker.
ZTemplate is designed to prevent recursion and other types of runaway resource use, but for added
security the trusted resource concept described for FreeMarker is also required for ZTemplate templates.
Templates and the Web-Service
Template processing can run from the Web Service too, so long as the file being
converted contains the required processing-instruction or one is specified in the processing_instructions
property passed to convert (see convert (request)). The Template must be a trusted URL,
so to allow Templates to be uploaded to the service, BFO Publisher version 1.3 adds the trusted
key to files added to the store. This key can only be set by a user with the admin/trusted grant (see Access Control).
The way we expect this to work is as follows.
-
An admin user with the
admin/trustedgrant uploads template(s) to a shared folder. -
Later, a regular user uploads a datamodel as CBOR/JSON and converts that by referencing that template with a processing-instruction
Here’s the upload of the Template, as done by the admin user
POST ${BASEPATH}/store HTTP/1.1
Authorization: Bearer _…JWT with admin/trusted permission…
Content-Type: application/json
{
"type": "put",
"content_type": "text/html",
"path": "freemarker-templates/template.html",
"trusted": true
"content": …
}And here’s the conversion - the data is uploaded as a file, so is sent as JSON serialized as a string (if sending CBOR,
the data can also be application/cbor, serialized as a byte buffer).
The template is referenced with a processing instruction as shown. The data is the same as the JSON example above.
POST ${BASEPATH}/convert HTTP/1.1
Content-Type: application/json
{
"url": "data.json",
"lang": "en-US",
"put": [
{
"path": "data.json",
"content": "{\"user\":\Big Joe\",\"latestProduct\":{\"url\":\"products/greenmouse/html\",\"name\":\"green mouse\"}}",
"content_type": "application/json"
}
],
"extra_folders": ["freemarker-template"],
"processing_instructions": [
{
"type": "freemarker",
"data": "href=\"template.html\""
}
]
}Of course if the user doing the conversion has the admin/trusted grant, both the template and the datamodel
can be uploaded in a single pass. Templates are cached and reused, and as BFO Publisher will identify them by their
checksum it’s OK to upload them repeatedly if necessary - this will create extra network traffic, but not a lot
of extra processing.
FreeMarker include and import are supported, as are includes in ZTemplate (they’re the same concept).
Relative paths are resolved relative to the path of the Template file.
Both are loaded using BFO Publisher resource loader, so are treated the same was as any other URL (see Security).
As a rule of thumb, the URLs for these imported files should be relative in order to work without Security
implications.
Metadata
Metadata can be embedded in the source XML or HTML in a number of ways, all of which will be converted to XMP which is the native format for PDF. Typically there is a single XMP object for the whole document, created by merging all the metadata specified in the file.
| Some terminology: RDF is an XML syntax for describing Metadata [subject, property, object] triples, often based on the Dublin Core vocabulary. XMP is a subset of RDF used to describe digital media documents like JPEG, MP4 or PDF. RDFa defines additional properties added to HTML or XML source from which RDF Metadata can be derived, and Microdata is an alternative method for deriving Metadata from HTML, often based on the schema.org vocabulary. |
Traditional HTML metadata
<title>The Document Title</title>
<title lang="de">Der Dokumententitel</title>
<meta name="author" content="The Document Author">This is how most people think of metadata in HTML - the
title and
meta
elements can be used
to set the corresponding fields on the document. The vocabulary available with this approach
is very limited however, so if you want to set more than just title, author, subject etc.
then you need to look outside the HTML spec for inspiration:
<link rel="schema.DC" href="http://purl.org/DC/elements/1.1/">
<meta name="DC.date" content="2021-02-01">
<meta name="DC.identifier" content="urn:isbn:9781507760116">
<meta name="DC.contributer" content="Einstein, Albert">
<meta name="DC.contributer" content="Penrose, Roger">
<meta name="DC.contributer" content="Da Vinci, Leonardo">The Dublin Core™ Elements are part of the native Metadata schema of PDF, and BFO Publisher supports the approach recommended at https://www.dublincore.org/specifications/dublin-core/dc-html/ for embedding these properties (and of course this isn’t limited to Dublin Core). The only requirements here are:
-
A
<link>with arelproperty starting withschema., that maps the prefix to the schema namespace -
<meta>properties that begin with that prefix followed by a ".", and that define simple values. Repeated definitions of the same property will be assembled into a list.
This method of embedding Metadata in a document is by far the simplest, and is the one we recommend.
RDF Metadata blocks
SVG has a native method for embedding structured metadata - the <metadata> element contains RDF content, which BFO Publisher will directly embed into the generated PDF.
<svg>
<title>The SVG title</title>
<desc>The SVG description</desc>
<metadata>
<rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#">
<rdf:Description about="" xmlns:cc="http://web.resource.org/cc/">
<cc:license rdf:resource="http://creativecommons.org/licenses/by-nc-sa/2.5/" />
</rdf:Description>
</rdf:RDF>
</metadata>
</svg>While there is no direct equivalent to this tag in HTML, there is a recognised approach for
embedding arbitrary XML in a PDF: the <script> tag.
<script type="application/rdf+xml">
<rdf:Description xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#" rdf:about="">
<mail:headers xmlns:mail="http://example.com/ns/mailschema/">
<rdf:Seq>
<rdf:li rdf:parseType="resource">
<mail:name>delivered-to</mail:name>
<mail:value>user@example.com</mail:value>
</rdf:li>
<rdf:li rdf:parseType="resource">
<mail:name>subject</mail:name>
<mail:value>email subject</mail:value>
</rdf:li>
</rdf:Seq>
</mail:headers>
</rdf:Description>
</script>Set the type of the script to application/rdf+xml and any content within the script tag will be parsed as
an RDF (an individual RDF description can also be used, as shown here). This functions identically to the
SVG <metadata> element.
The <script> element is used because - uniquely, in HTML - its content is always parsed as text, which
makes it particularly suitable for embedding XML data. When parsing XML source files, the content should be wrapped
in a CDATA block to avoid any parsing issues.
|
| The XMP used in PDF is a subset of the RDF used in SVG metadata, and while publisher will attempt to convert from one to the other, some concepts are impossible to represent in XMP. For maximum compatibilty, make sure the RDF has a single subject, avoid the use of typed nodes. |
<link rel="meta" type="application/rdf+xml" href="https://example.com/schema/boilerplate.xml"/>As an alternative to embedding the XML directly into the file, a
<link rel="meta">
can be used - the
content is the same as with <script>, but this time it’s stored in an external file.
Although this technique is fairly
widely used it’s not standardized, however
it is particularly useful when building an XMP document as it lets us import boilerplate
sections of XMP. For example, when generating PDF/A-2 or PDF/A-3 files that require a custom XMP extension schemas,
a good approach is to store the RDF defining that schema in an external file, then include it using this mechanism.
RDFa and Microdata 1.4
HTML documents have the option of using either RDFa or Microdata to build structured metadata directly from the document content. Commonly used for SEO on websites, this method is perhaps less common for document-level metadata. BFO Publisher can process both RDFa and Microdata to generate XMP Metadata to embed in a PDF, but note that by design, an XMP Metadata stream in PDF is limited to a single subject.
The PDF itself is the subject of the primary Document Metadata, and secondary Metadata may be associated with assets in the PDF, such as bitmap images. A tagged PDF (see Tagged output) may also contain secondary Metadata associated with tags in the Structure Tree. In BFO Publisher, any element designated as a scope and which generates a tag in the PDF can have Metadata, but the vast majority of PDF software does not expose this Metadata and there is no practical way for multiple XMP Metadata objects to refer to eachother. So this is of limited practical use and is disabled by default, but can be changed with two environment properties, one each for Microdata and RDFa.
| Name |
bfo-metadata-rdfa | bfo-metadata-microdata |
| Value |
|
| Description |
Determines which elements in the document will generate metadata from embedded RDFa
or Microdatao properties. The default value of |
Secondary Metadata will be created under some other specific circumstances: if the generated PDF
has tags and the element is an <svg>, <img>, <iframe>, <object> or <embed> referring to a
document with metadata, that metadata will always be embedded in the PDF. If the embedded
document is a bitmap image (eg JPEG) containing XMP metadata, that XMP will be associated with the bitmap
even if the generated PDF is not tagged.
|
Assuming the default value of root remains unchanged, a single subject places some fairly severe constraints
on the Metadata.
So the examples discussed below will be much simpler than the full range available in RDFa and Microdata.
RDFa
The native Metadata format of PDF is XMP, which is based on RDF. So RDFa is certainly the more natural of the two embedded formats and is a better choice for structured markup. The W3C RDFa primer at https://www.w3.org/TR/rdfa-primer/ is a good place for more information on the format, and below is a simple example which sets some of the primary PDF Metadata properties using RDFa. Note RDFa is very flexible; we’re showing one of many ways to do this.
<!DOCTYPE html>
<html lang="en" vocab="http://purl.org/dc/elements/1.1/">
<h1 property="title">The Document Title</h1>
<p>
By
<cite property="creator">John Doe</cite>
and
<cite property="creator">Max Mustermann</cite>,
on
<time property="http://ns.adobe.com/xap/1.0/CreateDate" datetime="2024-03-20 10:50Z">
20 March 2024
</time>
</p>
<main>
...
</main>
</html>The RDF construction <meta property="title">Title</meta> (commonly seen in eBooks)
will work in XML documents but not HTML, which defines <meta> as a childless element:
the HTML parser will reparent any children it contains.
An XML version of the above example with an extra <meta> added could look like
<!DOCTYPE html>
<html lang="en" xmlns:dc="http://purl.org/dc/elements/1.1/"
xmlns:xmp="http://ns.adobe.com/xap/1.0/CreatorTool"
xmlns="http://www.w3.org/1999/xhtml">
<meta property="xmp:CreatorTool">BFO Publisher</meta>
<h1 property="dc:title">The Document Title</h1>
<p>
By
<cite property="dc:creator">John Doe</cite>
and
<cite property="dc:creator">Max Mustermann</cite>,
on
<time property="xmp:CreateDate" datetime="2024-03-20 10:50Z">20 March 2024</time>
</p>
<main>
...
</main>
</html>Microdata
Microdata is a competing format to RDFa, although both can be used in the same Document (an excellent way to make an confusing topic even more so).
RDFa and Microdata both generate Metadata triples, but Microdata is based around the vocabulary from schema.org and is more focused on SEO for websites. It’s perfectly valid to embed Metadata from schema.org into a PDF, but as the native vocabulary for PDF metadata is based on Dublin Core it is unlikely that PDF processors will be able to extract much meaning from it.
In the schema.org vocabulary a PDF is probably a DigitalDocument, and an adaptation of the same example shown above would look something like this
<!DOCTYPE html>
<html lang="en" itemtype="https://schema.org/DigitalDocument">
<h1 itemprop="name">The Document Title</h1>
<p>
By
<cite itemprop="author">John Doe</cite>
and
<cite itemprop="author">Max Mustermann</cite>,
on
<time itemprop="dateCreated" datetime="2024-03-20 10:50Z">20 March 2024</time>
</p>
<main>
...
</main>
</html>Forcing HTML Microdata to use the Dublin Core vocabulary is also possible, although without
the concept of an itemtype in RDF it’s a little verbose.
The direct equivalent of the RDFa example using Microdata syntax would be
<!DOCTYPE html>
<html lang="en">
<h1 itemprop="http://purl.org/dc/elements/1.1/title">The Document Title</h1>
<p>
By
<cite itemprop="http://purl.org/dc/elements/1.1/creator">John Doe</cite>
and
<cite itemprop="http://purl.org/dc/elements/1.1/creator">Max Mustermann</cite>,
on
<time itemprop="http://ns.adobe.com/xap/1.0/CreateDate" datetime="2024-03-20 10:50Z">
20 March 2024
</time>
</p>
<main>
...
</main>
</html>Standard Metadata
BFO Publisher will embed several standard fields in all documents it generates by default:
the creation date, last-modified date,
the name of the software that created the PDF, and a few other fields required for PDF processing.
By default it will also embed the start of an audit trail of actions made to the PDF
(the xmpMM:History Metadata property), which begins with the
conversion from the source HTML or XML to PDF. This includes the URL of the source document,
and as this is a potentially sensitive piece of information this is controllable with an environment variable
| Name |
bfo-metadata-location |
| Value |
|
| Description |
which URL, if any, to embed in the Metadata audit trail in the PDF. |
Text
Fonts
Fonts are loaded exactly as specified in https://www.w3.org/TR/css-fonts-4/, which
is fully supported except for the sections relating to variables fonts. The
deprecated embedded-opentype and svg font formats are not supported.
Some features of OpenType are unsupported, and these can be tested using the
font-tech() query from https://www.w3.org/TR/css-conditional-5/#at-supports-ext or the
the tech() function from https://www.w3.org/TR/css-fonts-4/#font-technologies-formats.
The full list is below.
| Tech | Support | Notes |
|---|---|---|
features-opentype |
✓ |
OpenType layout in all languages with CFF or GLYF shapes |
features-aat |
- |
Apple AAT layout is unsupported |
features-graphite |
- |
SIL Graphite layout tables are unsupported |
variations |
- |
OpenType Variable fonts are unsupported |
colr-colrv0 |
✓ |
Supported |
colr-colrv1 |
- |
OpenType 1.9 introduced a new COLR table format which is unsupported |
colr-svg |
✓ |
Supported |
colr-sbix |
- |
Apple SBIX color fonts are unsupported |
colr-cbdt |
✓ |
Supported |
palette |
✓ |
Supported |
incremental |
✓ |
The "range request" approach is supported (see below) |
As OpenType Variable fonts are unsupported,
the CSS properties font-variation-settings and font-optical-sizing
are unrecognised, as are the
font-named-instance and font-variation-settings descriptors.
Incremental Loading
Incremental loading is a new idea in CSS, but one which the PDF Library
underlying BFO Publisher has unwittingly supported for years.
When this tech is specified on an OpenType or Truetype font (not WOFF or WOFF2), the
font is loaded over HTTP and the server supports HTTP Range, only the
required sections of the font will be downloaded.
For very large fonts where only a few glyphs are expected to be used, this can speed up processing and reduce network traffic - although as only the required used glyphs are embedded in the PDF, the size of the final PDF will be unchanged.
/* We're unlikely to use more than a few glyphs in the bold version
* so load it incrementally
*/
@font-face {
font-family: "Noto Sans CJK TC";
font-weight: 400;
src: url("http://example.com/NotoSerifCJKtc-Regular.otf") format(opentype);
}
@font-face {
font-family: "Noto Sans CJK TC";
font-weight: 700;
src: url("http://example.com/NotoSerifCJKtc-Bold.otf") format(opentype) tech(incremental);
}PDF Fonts
The @font-face rule will load a font from a URL and embed it in the PDF, but PDF also
supports a number of fonts which can be used without embedding anything.
These are pre-defined in the user-agent stylesheet of BFO Publisher,
so are available to every document.
-
PDF Times,PDF Helvetica,PDF Courier- these three fonts cover the glyphs required for English, French, German, Portuguese, Italian, Spanish, Dutch (no "ij" ligature), Danish, Swedish, Norwegian, Icelandic, Finnish, Polish, Croatian, Czech, Hungarian, Romanian, Slovak, Slovenian, Latvian, Lithuanian, Estonian, Turkish, Catalan (no Ŀ), Basque, Albanian, Rhaeto-Romance, Sorbian, Faroese, Irish, Scottish, Afrikaans, Swahili, Frisian, Galician, Indonesian/Malay and Tagalog (corrections and additions to this list welcome). They also include a number of extended punctuation characters. The full character map is available at https://bfo.com/products/pdf/docs/map-normal.pdf -
PDF Symbol- stylistically identical toPDF Times, this is made up of math symbols. The map is available at https://bfo.com/products/pdf/docs/map-symbol.pdf -
PDF ZapfDingbats- stylistically identical toPDF Times, this is most of the Unicode Dingbats table at U+2700 to U+27C0. The map is available at https://bfo.com/products/pdf/docs/map-zapf.pdf
The five fonts above, along with the bold, italic and bold-italic variants of
PDF Times, PDF Helvetica and PDF Courier make up what’s commonly known as the
Standard 14 Fonts in PDF. Every glyph in these fonts is guaranteed to be available
on all PDF viewers.
There are also some semi-standard CJK fonts available to PDF
-
PDF Mincho- a variable stroke-width (serif-like) font for Japanese: map -
PDF Kaku Gothic- a fixed stroke-width (sans-serif like) font for Japanese: map -
PDF Songti TC- a variable stroke-width font for Traditional Chinese: map -
PDF Heiti TC- a fixed stroke-width font for Traditional Chinese: map -
PDF Songti SC- a variable stroke-width font for Simplified Chinese: map -
PDF MyeongJo- a variable stroke-width font for Korean: map -
PDF Gothic KO- a fixed stroke-width font for Korean: map
The range of glyphs available to each of these is defined but of course is much larger,
and also tends to be expanded with new PDF revisions. Consequently whether a glyph
can be shown on a PDF viewer or not is less well defined - for example, although the
PDF Mincho font includes the Reiwa era glyph (U+32FF ㋿) added in 2019, it’s
possible that the PDF viewer displaying the glyph may not have it.
Finally, BFO Publisher ships with the STIX Two Math font, which is pre-loaded
for all documents and is used to display MathML.
PDF Fonts and PDF/A
PDF/A, PDF/UA and PDF/X require all fonts are embedded, so BFO Publisher ships with embeddable versions of the Standard 14 Fonts. No change is required to use these: if the PDF output format requires it, the embedded versions will be used automatically.
The same is not true for the CJK fonts listed above, and attempting to use those fonts in a PDF/A file will cause an error to be thrown during conversion. An embedded font must be used instead.
Local Fonts
BFO Publisher does not ship with any local fonts, and does not use the OS fonts directory. Fonts can only be loaded by creating a CSS stylesheet for those fonts and including it.
This process can be automated by using a BFO Publisher extension: the fonts URL scheme.
It’s very similar to the file scheme, except that instead of returning the font at the
specified path, it returns a CSS file describing the font. If the path is a directory the
CSS file will describe all fonts contained in that directory. This makes it easy to add system
fonts by simply including fonts:///c:/windows/fonts as a stylesheet.
there is a small cost to adding too many fonts - first, they all have to be parsed to
determine which characters they contain, which is done the first time the fonts URL is accessed.
Second, if a character is used which is not in the current font, all fonts loaded this way
will be checked and the first that contains the glyph will be used. For this reason we do not
generally recommend adding every font you can find.
|
The font URL is a live URL; it will be updated if new fonts are added or removed to that
folder
Generic Fonts
CSS defines several generic font families which should always be available, but as PDF does not use the operating system fonts this gets a bit more complicated. BFO Publisher maps these generic fonts to named fonts depending on the element’s language, (typically just the script), and this mapping can be changed. The default mappings are listed below; see https://www.w3.org/International/articles/language-tags/ for an explanation of languages in XML and HTML
| Generic | Languages | Mapped to |
|---|---|---|
serif |
*-Latn |
|
serif |
*-Jpan, *-Hrkt, *-Hira, *-Kana |
|
serif |
*-Hant, *-Hanb, *-Bopo |
|
serif |
*-Hans, *-Hani |
|
serif |
*-Kore, *-Hang, *-Jamo |
|
sans-serif |
*-Latn |
|
sans-serif |
*-Jpan, *-Hrkt, *-Hira, *-Kana |
|
sans-serif |
*-Hant, *-Hanb, *-Bopo |
|
sans-serif |
*-Kore, *-Hang, *-Jamo |
|
monospace |
*-Latn |
|
math |
* |
|
Other mappings might be preferred - for example, instead of using the standard PDF Fonts for these generic familes, you might prefer to map all generic familes to the Noto fonts, or to fonts available in your system font directory.
To enable this, BFO Publisher includes some system stylesheets which will do this for you.
They are optional but can be included in any document as a user or user-agent stylesheet.
| Stylesheet | Result |
|---|---|
classpath:data/fonts-noto-cjk.css |
|
classpath:data/fonts-noto-core.css |
|
classpath:data/fonts-noto.css |
|
classpath:data/fonts-os-cjk.css |
|
classpath:data/fonts-os.css |
|
classpath:data/fonts-os-core.css |
|
This is inevitably complex but it will usually boil down to this:
-
You want to use the Noto fonts for all generic familes? Include the three
notostylesheets listed above. and make sure the fonts you need are loaded with@font-face -
You want to use typical OS fonts for all generic familes? Include the three
osstylesheets listed above. -
You’re happy with the defaults for Latin and the CJK scripts, but want to add generic families for other languages? Include the
fonts-os.cssorfonts-noto.cssas preferred.
Finally, all this can be customized - the stylesheets above can be retrieved by calling the
Report.getResource() method
(see API Usage for details) or extracted from the JAR file, and used as a basis for a cutom mapping.
In all these cases, you will need load the fonts by creating a @font-face rule for them.
Only the standard PDF Fonts listed in the previous section can be used without a @font-face.
|
Hyphenation
Hyphenation is pre-supported for a number of languages, using the code and Hyphenation patterns from Apache FOP. Those patterns in turn were derived from TeX.
New hyphenation patterns can be loaded using a <link> element, as shown below. Either the FOP-style XML
format (with a root element of <hyphenation-info>) or UTF-8 TeX patterns (which should look like
\patterns{ … } - some
examples)
can be used.
<head>
<link rel="hyphenation" lang="ta" href="hyph-ta.tex"/>
<style>
:lang(ta) {
hyphens: auto;
hyphenate-limit-chars: auto 3 auto;
}
</style>
</head>Language matching is done using standard BCP47 rules;
setting lang="en-GB-oxendict" will look first
for a hyphenation dictionary with that exact
language tag, falling back to en-GB then en.
Hyphenation requires a language to be set:
with no lang attribute (set or inherited),
no hyphenation will take place.
Color
Color in CSS has been sRGB only for many years, but the 2021 publication of CSS Color 4 has finally brought wide gamut RGB and Lab color to the web. The specification is very RGB-focused (sRGB only uses ⅔ of the gamut of modern displays, many of which are capable of Display P3). But it also brings many improvements which are great for print, like Lab and LCH color.
BFO Publisher fully supports all of CSS Color 4 and a good amount of the
evolving CSS Color 5 revision too.
With the exception of device-cmyk(), all of the colors used in CSS are
calibrated - their color values are defined exactly in a way that allows
them to be reproduced reliably on screen and in print.
RGB and Lab/LCH
PDF itself has long supported calibrated colors, and allows them to be defined in CIELab, or by way of an embedded ICC profile. So long as they’re within gamut, any calibrated color can be converted to any other without loss. Which means we’re able to support all the colors now available in CSS, also without loss.
With the explosion of new color-spaces available we won’t list every syntax here - if it’s in the specification, we support it. The following table shows how each is stored in PDF.
| Type | CSS Color Spaces | PDF Storage |
|---|---|---|
RGB |
sRGB, sRGB-linear, Display P3, Adobe™ RGB, ProPhoto, Rec.2020 |
ICC profile |
Hue-based sRGB |
as for sRGB |
|
Lab/LCH |
Lab |
|
XYZ |
Lab |
BFO Publisher ships with the reduced-size ICC profiles for the various RGB spaces listed above, created and placed into the public domain at https://github.com/saucecontrol/Compact-ICC-Profiles.
CMYK and ICC colors
CSS Color 5 defines a syntax for device-dependent CMYK color - the only type of uncalibrated color available to CSS.
div { color: device-cmyk(0 0 0 1);
div.alpha { color: device-cmyk(0 0 0 1 / 0.5); /* With 50% alpha */As of 2022 this syntax is widely support by other print CSS engines, although
not yet by browsers. Another common syntax which was in wide use before the
standardization in CSS is the cmyk() function, which is not supported in BFO
Publisher by default. However it can be added by setting the bfo-sys-colors
environment variable:
| Name |
bfo-sys-colors |
| Value |
none | <string> <string>* |
| Description |
A list of one or more strings, naming the non-standard color functions
which may be encountered in existing print documents and should be recognised by
BFO Publisher. Currently defined values are |
For example to use the legacy cmyk() function to define CMYK color:
@bfo env {
bfo-sys-color: "cmyk";
}
div { color: cmyk(0, 0, 0, 1);Device-dependent color is fine if you’re happy with whatever pigments the printer has, but if you want calibrated CMYK color you will need to reference an ICC Profile by its URL.
For example, to generate CMYK color that is calibrated to "FOGRA 39", also variously known as ISO12647-2:2004 or "ISO Coated v2", you would need the URL of a suitable FOGRA39 ICC profile.
@color-profile --fogra39 {
src: url("http://example.com/path/to/fogra39.icc");
}
div { color: color(--fogra39 0 1 0 0);The @color-profile
at rule is defined in CSS Color 5,
and takes a profile name - which must
begin with a double-hyphen - and a single property, src, which is the URL of the ICC profile to embed.
To reference this new color-space use the standard CSS color() function as shown.
While CSS allows any type of ICC profile in theory, PDF only accepts CMYK, RGB or grayscale profiles
that are of type prtr or mntr - printer and monitor, not scanner or other types intended
for input devices rather than output.
Anchoring device-cmyk
The @color-profile rule can also be used to to anchor any device-cmyk colors to an ICC profile.
This is required for PDF/A, PDF/UA and PDF/X documents that make use of uncalibrated CMYK. It’s identical
to the example shown above except the name is device-cmyk:
@color-profile device-cmyk {
src: url("http://example.com/path/to/fogra39.icc");
}
div { color: device-cmyk(0 1 0 0);We strongly recommend this approach for CMYK content instead of using the color() function; it’s
simpler to manage (device-cmyk is easier to remember than a custom name), causes less problems
with overprint, and will also catch any CMYK images that don’t reference an ICC profile which
would otherwise remain uncalibrated.
Spot colors and Overprint
CSS does not yet have a syntax for spot colors - also called separations, these can be thought of as additional pigments which are added to the printer alongside Cyan, Magenta, Yellow and Black.
The HP Indigo range of industrial printers, for example, has a white pigment called
CMYK White, which can be used when printing onto colored stock.
|
To define spot colors in BFO Publisher, we’ve added two custom descriptors to the @color-profile
rule which can be used instead of src: -bfo-components and -bfo-fallback:
| Name |
-bfo-components |
| Applies to |
the |
| Value |
|
| Name |
-bfo-fallback |
| Applies to |
the |
| Value |
|
These properties takes a comma-separated list of component names - the name of the ink,
e.g. Pantone Reflex Blue C, and their corresponding fallback colors. The two lists should be the
same length, and in the vast majority of cases they will both be a single item, to define a Spot color
(lists of more than one ink define what’s called a Device-N color in PDF parlance).
The fallback color(s) should typically be in device-cmyk or another CMYK space, but RGB is also allowed.
More exotic spaces such as Lab and LCH can be used, but any space that is stored in PDF
using the Lab color-space is a bit complicated when it comes to gradients, so be careful. Typically the
Spot color name is a well known name from the PANTONE™ range or similar, and is being used because the
intended output device is aware of it colorimetry. The fallback will only be used on a device that doesn’t
know about that ink, such as a screen or regular desktop printer, so an approximate device-cmyk() is fine.
Once you’ve defined a new @color-profile rule with both two properties, you can use it like any other.
@color-profile --reflexblue {
-bfo-components: "PANTONE Reflex Blue C";
-bfo-fallback: device-cmyk(1 0.723 0 0.02);
}
.a {
color: color(--reflexblue 1); /* 100% Reflex Blue */
}
.b {
color: color(--reflexblue 0.5); /* 50% Reflex Blue */
}If you want to create a
gradient
between two spot colors,
or between a spot color and a process color pigment,
create a @color-profile rule with all the required components of the gradient.
Your new color-space can have as many components as you like - as we’re typically
using additive colors any 0 values mean no ink, so keep the component at
zero to disable it. However that all gets a bit complex, so the example here just
show two inks.
@color-profile --blue-red {
-bfo-components: "PANTONE Reflex Blue C",
"PANTONE Warm Red C";
-bfo-fallback: device-cmyk(1 0.723 0 0.02),
device-cmyk(0 0.75 0.9 0);
}
@color-profile --blue-black {
-bfo-components: "PANTONE Reflex Blue C",
"Black"
-bfo-fallback: device-cmyk(1 0.723 0 0.02),
device-cmyk(0 0 0 1);
}
.a {
/* A gradient from 100% "Pantone Reflex Blue C"
to 100% "Pantone Warm Red C"
*/
background: linear-gradient(to right,
color(--blue-red 1 0), color(--blue-red 0 1));
}
.b {
/* A gradient from 100% "Pantone Reflex Blue C"
to 100% process black.
*/
background: linear-gradient(to right,
color(--blue-black 1 0), color(--blue-black 0 1));
}Another use for Spot colors is to convey special pseudo-colors, which are really just instructions for the output-device: perhaps representing cut or score lines, for example, or an area to apply varnish or glue. Spot colors with overprint are a good choice here aa they allow these lines to be marked without interfering in any other color on the page. Drawing these on a PDF Layer allows them to be easily removed during proofing.
| Name |
-bfo-overprint: |
| Applies to |
the |
| Value |
|
Setting -bfo-overprint to true in a @color-profile ensures that any colors created in
that color-space are drawn with overprint. Overprinting is a concept unique to print;
normally any inks drawn on a page replace all other inks in that area. When overprinting,
only the inks in use by that color are replaced. It’s a difficult one to visualise on
screen, but take a close look at the color components to get an understanding - the
example shows drawing first in a CMYK color, then overwriting that with
a spot-color in our custom colorspace: first normally, then with overprint.

To put all this together, imagine we want to to create our PDF with a special Fold pseudo-color which indicates to our ISO19593-aware print workflow that a fold should be made at that point. We don’t want this fold line to obscure the color behind it - we want it to overprint.
<svg>
<style>
@color-profile --fold {
-bfo-components: "Fold"
-bfo-fallback: device-cmyk(0 0 0 1);
-bfo-overprint: true;
}
.fold {
stroke: color(--fold 1);
-bfo-layer-type: layer;
-bfo-layer-name: "Fold";
-bfo-layer-processing-step: "Structural.Folding";
}
rect {
fill: device-cmyk(0.2 1 0.3 0);
}
</style>
<rect x="0" y="0" width="400" height="100"/>
<line class="fold" x1="200" y1="0" x2="200" y2="100"/>
</svg>Registration colors
Finally, printers sometimes make use of registration black - a color which uses all inks
available, so that the marks will appear on all plates (the term rich black is sometimes
heard too, which is device-cmyk(1 1 1 1). The two are identical unless spot colors are
used in the document - spot-color plates will not be marked by rich black, only
registration black).
We’ve added a special color-profile to the list predefined in CSS Color 4, called registration.
Printer marks (see the marks CSS property) are drawn in this color.
@page {
@bottom-right {
content: env(bfo-location);
/* draw 100% in every ink on the output device */
color: color(registration 1);
}
}Forms
HTML has form fields and PDF has form fields, but the underlying model between the two environments is quite different. BFO Publisher tries to consolidate these two views as much as possible, but some significant differences remain.
HTML:
-
has multiple independent
<form>elements -
JavaScript access to fields uses the HTML DOM
-
fields do not need a name. When names are specified they should be unique, but nothing will break if they’re not.
-
CSS can be used to style fields in a particular state, for example using the
:checked,:active:hoverpseudo-classes. -
Although more limited than general HTML elements, form fields can be largely restyled with CSS.
appearance:nonecan be used to override -
A click on the
<label>element is treated as a click on the field, which opens some clever options for restyling checkboxes and radio buttons -
Form submission is can be
getorpost, with apostmethod of encoded or multipart depending on theenctypeattribute
PDF:
-
has one document-wide Form
-
JavaScript access to fields uses the PDF JavaScript environment
-
every field must have a name - if they don’t, one is auto-assigned
-
field names must be unique across the entire document
-
as a special case, two fields with the same name must have the same type, and will share the same value. If two fields with the same name have different types, conversion will fail.
-
state-related pseudo-classes
:checked,:hoverand:activecan be used in a limited way (see Styling Form Fields) -
Styling of the dynamic content of form-fields (ie. text) is extremely limited - only font size, style, family and color can realistically be altered.
-
appearance:noneis not supported. -
clicking on the
<label>element does nothing. -
Form submission can be
post,fdf,xmlorpdf. Thepostmethod is not controllable, but is usually encoded.
Within these limitations BFO Publisher will overlay the HTML model onto the PDF model as closely as possible. All HTML5 input types and attributes are supported, with the following caveats:
| HTML Element | Comment |
|---|---|
input type= |
Identical to |
input type= |
Identical to |
input type= |
Identical to |
input type= |
Identical to |
input type= |
Supported but the font cannot be changed |
input type= |
Supported but the font cannot be changed |
input type= |
Adobe Acrobat styles this as a text field with a special |
input type= |
Adobe Acrobat styles this as a text field with validation on the entered value. |
input type= |
Adobe Acrobat styles the date portion of this as |
input type= |
Styled as |
input type= |
Identical to |
input type= |
Identical to |
input type= |
Theoretically supported, but in practice appears unrecognised in Adobe Acrobat or other viewers. |
input type= |
Identical to |
textarea |
PDF treats this as |
| HTML Attribute | Comment |
|---|---|
|
Supported on |
|
Supported on |
|
Partially supported on |
|
Supported |
|
Supported since 1.4[.newfeature]1.4 |
|
Supported |
|
Not supported |
|
Not supported |
|
Not supported |
|
Not supported |
|
Not supported |
|
Supported on |
|
Supported on |
|
Supported since 1.4[.newfeature]1.4 |
|
Not supported |
|
Not supported |
|
See earlier paragraph for details on how this differs. |
|
A property custom to BFO Publisher which will comb the field, spacing the number of characters specified by |
Styling Form Fields
HTML does not make it easy to style form fields, and various hacks have evolved over the years
to do so, mostly for checkbox and radio-button fields. Most involved hiding the <input> and
styling the <label> element, which won’t work in PDF: <label> is drawn to the page, so is fixed
and doesn’t interact with the field.
There are techniques for styling form fields in BFO Publisher which are presented here, but with the caveat that presentation of fields is an area that varies across PDF viewers.
Styling dynamic fields
A ''dynamic field'' in PDF is one where the appearance will need to be regenerated by the PDF viewer
as the value changes, such as text fields and <select>. BFO Publisher can style the initial appearance
of the field, but the PDF viewer will recreate the appearance when the value changes, and each will do
it differently. The only properties that matter here are font-family, font-style, font-weight,
font-size, color and the HTML property direction. Pseudo-classes like :active, :error and
:blank are not used. For <textarea> fields, the exact position of each line within the field cannot
be controlled; line-height, vertical-align etc. have no effect.
Styling static fields
Buttons, checkboxes and radio-buttons can be comprehensively styled in BFO Publisher, and in release
1.4 1.4 the :checked, :active and :hover pseudo-classes now work for these fields.
There are still limits: the border-box of a form field cannot change size or shape, and this
includes paint overflow size resulting from properties like box-shadow, filter and overflow
- none of which are likely to work as expected for form-fields.
However beyond that styling with :active and :hover works as you’d expect, although support for
:hover in particular is limited in some PDF viewers, and can lead to display bugs in others.
button {
border: 1px solid black;
background: #eee;
}
button:active {
border-color: red;
color: red;
}Styling radio-buttons and check-boxes is quite different to browsers, however. We make use of the content
property to style these - the default stylesheet value of content:normal will generate a standard appearance,
but with an appropriate font the appearance can be drastically changed.
<style>
input[type=checkbox] {
font-family: "Noto Color Emoji";
border: none;
width: 1rem;
height: 1rem;
vertical-align: top;
padding-top: calc(1rem * 0.1);
font-size: calc(1rem * 0.7);
opacity: 0.2;
content: "😐";
}
input[type=checkbox]:checked {
content: "😀";
opacity: 1;
}
</style>
<p>
Off <input type="checkbox"><br/>
On <input type="checkbox" checked>
</p>
This works, but there is necessarily some “messing about” with CSS styles to position the text within
the space (as can be seen in the example). A better alternative is to set the content property to the URL of an image,
which will be stretched to fit the checkbox. BFO Publisher styles the default appearance of radio buttons
and checkboxes this way, with a data URL containing an SVG - it’s a simpler and more flexible solution, and one
we recommend:
input[type=checkbox] {
border: none;
width: 1em;
height: 1em;
content: url("data:image/svg+xml,<svg ... /svg>");
}
input[type=checkbox]:checked {
content: url("data:image/svg+xml,<svg ... /svg>");
}Digital Signatures
BFO Publisher supports digitally signing the PDF it creates by using the
HTML <object> element with a special type value of bfo/signature.
| Only the PDF output format can be digitally signed. When used with any other output format, only the visible appearance of the signature will be generated. Also note that only one signature can be applied in PDF - this is a limitation of the PDF signing process. |
<html>
<body>
This document contains a digital signature
<object type="bfo/signature">
<param name="keystore" value="path/to/keystore.pkcs12">
<param name="alias" value="myidentity">
<param name="password" value="secret">
<param name="reason" value="Royal Seal of Approval">
<img src="Richard_III_signature_1.svg" style="width:100%" alt="Signature image"/>
Richard III<br/>
Leicester, LE1 5DB
</object>
</body>
</html>An HTML <object> may have <param> children to configure the object; any other children
are displayed as normal (as they would be for an HTML <object> with a missing source).
Most of the parameters are optional, and which apply will depend on the engine.
- engine
-
The Signature Engine to use for the signature. Option are the
defaultengine (the default) andglobalsign.dssorglobalsign.qss, which use the GlobalSign Digital Signing Service™ or Qualified Signing Service, described at https://www.globalsign.com/en/digital-signatures. - keystore
-
The URL of the Key Store containing the digital identity used for signing. BFO Publisher recognises the PKCS#12, JKS and JCEKS Key-Store types normally used by Java, and the identity can also be loaded from a file with a PEM-encoded Private Key and one or more PEM encoded X.509 certificates. This is the only parameter that is always required.
- alias
-
The alias to use from the Key Store. Only required for Key Stores that contain more than one key such as JKS, this parameter may also be specified as the
aliasfragment parameter of thekeystoreURL, for example.path/to/keystore.jks#alias=myidentity. Multiple fragment parameters are encoded exactly like query parameters. - serial
-
The serial number of the identity to use from the Key Store - this serves the same purpose as
aliasand is also optional. It may be combined wihcnordn. Like alias, it may also be specified as a fragment parameter in thekeystoreURL. - cn
-
The X.500 common name of the identity to use from the Key Store - again, like
aliasorserialthis is a method of choosing an identity from a Key Store that contains more than one, and so is optional. It may be combined wihserialand may may be specified as a fragment parameter in thekeystoreURL. - dn
-
The X.500 distinguished name of the identity to use from the Key Store. Only the fields specified will be matched. This is here for completeness but
cnis usually a simpler choice. It may be specified as a fragment parameter in thekeystoreURL. - password
-
The password to access the chosen identity from the Key Store. It may be specified as a fragment parameter in the
keystoreURL. If not specified, it will be requested via a callback (see Secrets and Authentication). - store-password
-
For Key Store formats that allow different passwords for the key and the store itself, this specifies the store password. It may be specified as a fragment parameter in the
keystoreURL. If not specified, it will be requested via a callback (see Secrets and Authentication). - title
-
A descriptive title for the signature field, this serves as the description of the field for accessibility purposes (see [PDF/UA])
- reason
-
The Reason for signing, a text string stored with the signature.
- location
-
The Location of signing, a text string stored with the signature.
- contact-info
-
The Contact Information of the entity signing the document, a text string stored with the signature.
- author
-
The Author of the signature, a text string stored with the signature. If not specified, defaults to the common name of the signing identity
- changes
-
Which changes to allow to the PDF after signing. Values are
commentsto allow comments to be applied,fieldsto also allow form fields to be completed`,allto allow any changes allowed by the signature policy of the application displaying the PDF, ornoneto allow no changes at all (the default). - attestation
-
If the value of
changesis notall, this is an optional text string to be stored with the signature explaining anything affecting the legal integrity of the document. - tsa
-
The URL of an RFC3161 time-stamp server to time-stamp the signature. This parameter may be specified more than once to provide a list of servers, in case the first one is unavailable.
- hash
-
The digest algorithm to use for signing - the default is
sha256 - mode
-
The signature mode - values are
ltvfor PAdES Long Term Validation,pades(the default) for regular PAdES signatures, orlegacyfor non-PAdES. - size
-
The estimated size in bytes of the PKCS#7 object that will be generated. If unspecifed, BFO Publisher will estimate the size by doing a test signature first. This is usualy the best option unless you’re using a signing service that charges per signature. The value determines how much space is reserved for the signature and needs to be higher than the largest PKCS#7 object that might be generated.
- store-type
-
The type of Java
KeyStoreto create. This is not required for normal use - the type is automatically determined for regular software-based Key Stores. It’s required for non-standard extensions to Java, such as signing with the Amazon CloudHSM keystore when you would use a value ofCloudHSM.
The keys above apply to the default signature engine. The globalsign.dss and globalsign.qss engines
1.3
have different requirements:
- apikey
-
The API key required to access the GlobalSign Service. Required (but will be requested via a callback if missing (see Secrets and Authentication).
- apisecret
-
The API secret required to access the GlobalSign Service. Required, but will be requested via a callback if missing (see Secrets and Authentication).
- identity
-
For
globalsign.qss, an email address (which must have been previously been registered with the QSS service). Forglobalsign.dss, an X.500 identity which will be used for signing. Which X.500 fields apply, or whether it applies at all, will depend on the DSS service. Required, but will be requested via a callback if misssing (see Secrets and Authentication). - keystore
-
As for the
defaultengine, this is the path to a Key Store. Forglobalsign.dssorglobalsign.qsssignatures the Key Store contains the TLS client certificate issued by GlobalSign to access their service, rather than identity information for the signature. Thealias,passwordetc. properties also apply exactly as they do above.
PKCS#11 Hardware tokens
Key Store information can also be taken from an HSM (Hardware Security Module) - in fact, this is a requirement for signatures meeting the standards of the Adobe Approved Trusted List (AATL). We’ve written more on this topic at https://bfo.com/blog/2019/09/23/perfect_pdf_digital_signatures_eu_style/
The only change required to use a PKCS#11 hardware token is changing the URL of the Key Store to use the pkcs11
scheme, as defined in
https://tools.ietf.org/html/rfc7512
<html>
<body>
This document contains a digital signature
<object type="bfo/signature">
<param name="keystore"
value="pkcs11:object=Test%20Tester?pin-value=1234&module-path=/usr/lib/opensc-pkcs11.so"/>
Signature Here
</object>
</body>
</html>RFC7512 describes a number of parameters but not all are available for use with the Java PKCS#11 interface. Those that do apply are described here.
- object
-
This is the CKA_LABEL of the object to retrieve from the PKCS#11 device - effectively the
aliasof the identity on the keystore. It’s part of URL Path, and is required. - module-path
-
This is the path to the native library providing the PKCS#11 implementation to Java. It’s part of the URL Query String, maps to the
libraryparameter in Java’s PKCS#11 interface, and is required. - pin-value
-
This is the PIN value to retrieve the object from the PKCS#11 device - effectively the
password. Ifpin-valueandpin-sourceare both missing the standard callback mechanism will be used to prompt the user for the pin (see Secrets and Authentication). It’s part of the URL Query String, maps to thelibraryparameter in Java’s PKCS#11 interface, and is optional. - pin-source
-
This is the URL of a file containing the PIN value to retrieve the object from the PKCS#11 device. If
pin-valueandpin-sourceare both missing the standard callback mechanism will be used to prompt the user for the pin. It’s part of the URL Query String, maps to thelibraryparameter in Java’s PKCS#11 interface, and is optional. - slot-id
-
This is the CK_SLOT_ID to select on the PKCS#11 device - a number, typically 0 or 1. It’s part of the URL Path, maps to the
slotparameter in Java’s PKCS#11 interface, and is optional. - library-description
-
This is the CK_INFO libraryDescription - the description of the PKCS#11 library. It’s part of the URL Path, maps to the
descriptionparameter in Java’s PKCS#11 interface, and is optional. - java-nnn
-
Any fields in the URL Path or Query String that begin with
java-will be added (minus thejava-prefix) to the PKCS#11 interface configuration as specified. All are optional.
Other parameters may be specified but will be ignored.
Generating self-signed keys 1.4
During development it’s frequently useful to be able to sign documents with a temporary key.
As a convenience, BFO Publisher is able to generate self-signed keys without the need to reference
a key store by specifying a URL beginning with about:identity. Parameters include
- algorithm
-
the Java algorithm name, eg "SHA256withRSA or "ECDSA" (defaults to "SHA256withRSA"
- curve
-
for EC signatures, the curve to use, eg "secp256r1" (the default)
- provider
-
the name of a registered Java provider to use for key generation, eg "BC" (defaults to none)
- validity
-
the number of days the signature should be valid for (defaults to 30)
- keylength
-
for RSA keys, the number of bits; typically 1024 or 2048 (defaults to 1024)
- cn, ou, o, l, st, c
-
these fields are added to the X.500 identity, which otherwise defaults to
CN=test.
All this makes it very easy to create digitally signed PDFs for workflow testing:
<html>
<object type="bfo/signature">
<param name="keystore" value="about:identity"/>
Signed with a self-signed RSA-1024 / SHA-256 identity "CN=test"
</object>
</html><html>
<object type="bfo/signature">
<param name="keystore" value="about:identity?algorithm=ecdsa&validity=30&CN=internal&C=de"/>
Signed with a self-signed EC secp256R1 / SHA-256 identity "CN=internal C=de"
</object>
</html>Signature defaults
Each of the parameters specified will take their default values from an environment variable of the form
bfo-ext-signature-NNN where NNN is the parameter name. This allows information which might not be
available to the document author, such as the path to the keystore, to be specified in advance.
| Name |
bfo-ext-signature-nnn |
| Value |
string |
| Description |
set the default parameter values for any digital signatures. |
Using this approach, the PKCS#11 example above could have be specified like this:
<html>
<meta name="bfo-ext-signature-keystore"
content="pkcs11:object=Test%20Tester?pin-value=1234&module-path=/usr/lib/opensc-pkcs11.so">
<body>
This document contains a digital signature
<object type="bfo/signature">
Signature Here
</object>
</body>
</html>Obviously the environment variable can be specified externally to the source file rather than inline as shown here. Using the Overrides and Defaults controls from the web-service to set these properties would allow an identity used for authentication with the Web Service to preconfigure or control the identity used for signing documents.
Barcodes
BFO Publisher supports inserting dynamically created barcodes into the PDF. While it’s possible to create barcodes externally and insert them as a bitmap, the approach described here will be faster and give better resolution: the barcode is generated with vector graphics.
An HTML <object>
element with a special type value of bfo/barcode is used to insert
a barcode. An HTML5
<embed>
object can also be used if preferred, which allows using attributes instead of nested <param> tags.
<object type="bfo/barcode">
<param name="code" value="qrcode"/>
<param name="value" value="Testing Barcode"/>
<param name="unit" value="1mm"/>
<p>testing fallback</p>
</object>The parameters below can be used. Any unrecognised parameters will be ignored, as will any
other chidren to <object>. code and value are required, anything else is optional and
the defaults for those values depend on the code symbology.
- code
-
The barcode type - required.
- label
-
Either
true(the default) orfalse, controls whether the text value of the barcode is displayed. Does not apply to every type of barcode. - unit
-
The barcode unit-size. The exact meaning of this depends on the code, but for 1D codes like Code 128 it’s typically the width of the thinnest bar, and for 2D codes like QR-code it’s the size of the individual squares in the code.
- columns
-
For PDF417 barcodes, the number of columns to format the code - must be >= 1
- ecc
-
The error correction to apply. The generic values
none,minandmaxwill be mapped to whatever is appropriate for the chosen barcode type, and integer values can also be used, with0meaningnone,1meaningminand values increasing from there. - ratio
-
For variable width barcodes like Code 39, the ratio between thin and thick bars. Typically about 2.5
- bleed
-
The ink-bleed amount, specified as a length (or horizontal and vertical lengths separated with a space).
- value
-
The barcode value. Required.
Barcode types can be any of the following
-
qrcode -
code128 -
ean13 -
ean8 -
upca -
rm4scc(UK Royal Mail 4-state barcode) -
auspost4s(Australia Post 4-state barcode) 1.4 -
identcode(DeutschePost;leitcodeis a synonym) -
postnet(US Postal service) -
intelligentmail(US Postal service) -
databar -
databar-truncated(reduced heightdatabar) -
aztec -
datamatrix -
deutschepostmatrix(DeutschePostdatamatrix) -
code39 -
code39x(Code 39 Extended) -
code93 -
codabar -
interleaved25 -
itf14 -
itf14-box(ITF14 with the bearer box) -
pdf417(pdf417:2006andpdf417:2015are synonyms) -
pdf417:2001(see here for an explanation) -
pdf417:eci
The size of the barcode (the intrinsic size of the object, in CSS terminology) will be dynamically
calculated from the barcode type, value and unit and will include the minimal mandatory whitespace
around the barcode. It’s possible to override the size in HTML by setting the width or height attributes
on the <object> or in CSS, but be aware that for for some types this may distort the barcode.
Controlling size with unit is the preferred option.
Barcodes will respect many CSS properties like font-family, color and so on.
Although this author feels there is a special place in hell reserved for those who place an image over the
center of a QR-code, neatly obscuring all the error correction, it can be done by placing an absolutely
positioned image in the correct place:
<div style="position: relative; width: min-content">
<object type="bfo/barcode" style="display: block">
<param name="code" value="qrcode">
<param name="ecc" value="max"> <!-- give your image something to obscure -->
<param name="value" value="Testing Barcode">
</object>
<img src="kitten.png"
style="position: absolute; left: 0; top: 0; width: 100%; height:100%; object-fit: none">
</div>Footnotes and friends
Documents with many references often need a way to move those references out of flow. Three approaches are typical in paged media.
-
Footnotes - content is moved to the end of the current page.
-
Endnotes - content is moved to the end of the current chapter or section.
-
Sidenotes - content is moved to the side of the page.
-
Page floats - similar in effect to footnotes, content is moved to the top or bottom of the current page.
-
Column floats - like page floats, except content is moved to the top or bottom of the current column.
BFO Publisher supports all of these, and although the method of achieving each is quite different there are some common concepts which apply. Note that page floats and column floats do not have "calls" or "markers".
-
In all cases, content is moved away from where it’s defined in the document. To indicate this, a call is left at the point it was removed - typically a counter value, often super-scripted1 or placed within brackets(1).
-
The content is moved to a region where it is preceded by a marker containing the same counter value as the call, in exactly the same way as a list-marker marks a list item.

Footnotes
Footnotes are defined in https://www.w3.org/TR/css-gcpm-3/, so are at least semi-standardised in CSS.
To create a footnote set the float property on the footnote element to footnote.
This does several things
-
A
::footnote-callpseudo-element is created as a child of the floated element and positioned it at the call location on the page, where the footnote was originally. -
A
::footnote-markerpseudo-element is also created as a child of the floated element, and moved with the floated element to the@footnoteregion of the page.
The @footnote region is similar to the Page Margin Boxes, and can be styled the same way. It
is only created on a page when there are footnotes to place into it. The example above could be styled
with the following stylesheet.
Use counter-set: footnote 0 rather than counter-reset: footnote to reset a footnote counter
in the page margin; the second approach won’t work if counter scoping is implemented as specified.
|
<style>
@page {
counter-set: footnote 0; /* Reset counter to one on each page */
@footnote {
margin-top: 1em;
border-top: 1px black -bfo-dash(0 50%); /* Draw a top-border that's 50% of its length */
padding-top: 1em;
}
}
.note {
float: footnote;
}
::footnote-call {
/* These rules are the defaults; they're only shown for completeness */
counter-increment: footnote;
content: counter(footnote);
font-variant-position: super;
}
::footnote-marker {
/* These rules are the defaults; they're only shown for completeness */
content: counter(footnote);
}
</style>
<section>
<p>
Here is useful
<span class="note">
this information is not actually that useful, so we moved it to a footnote
</span>
information about something important, which we'll now go on about at length
</p>
</section>Endnotes
Endnotes are when content is moved to a later position in the document - the end of a chapter, a section, or the document. Endnotes don’t have standard support in CSS, but we can use CSS Regions (see https://www.w3.org/TR/css-regions-1/) to enable this.
| BFO Publisher has fairly limited support for CSS Regions; overflow is not yet supported. What is implemented is easily enough to handle endnotes. |
Unlike footnotes we have to create the Call, Marker and Region manually, but we can do this with pseudo-nodes so no change to the markup is required. Below is the previous example with the CSS changed to float the notes to the end of each section.
<style>
.note {
display: block;
counter-increment: endnote;
flow-into: endnote; /* Redirect the content to the "endnote" region */
}
.note::-bfo-call { /* A custom pseudo-class that allows a "call" to be created */
content: counter(endnote); /* for any element, not just footnotes. Like "::before", it's */
font-variant-position: super; /* created only if the "content" property is set */
}
.note::before { /* The is the "marker" for our endnotes */
content: counter(endnote) ". ";
}
section {
counter-reset: endnote;
}
section::after { /* This is the "endnote region". It's created at the end */
flow-from: endnote; /* of each section and will display any content previously */
display: block; /* directed to the "endnote" region". */
margin-top: 1em;
border-top: 1px black solid;
padding-top: 1em;
}
section::before { /* This pseudo-element exists only to flush the "endnote" */
flow-into: endnote; /* region content. Every time a new section is encountered, */
display: block; /* the "break-before:region" on this element will cause */
content: ""; /* any endnotes that follow it will be sent to the next */
break-before: region; /* "endnote region" rather than the previous one */
}
</style>
<section>
<p>
Here is useful
<span class="note">
this information is not actually that useful, so we moved it to a footnote
</span>
information about something important, which we'll now go on about at length
</p>
</section>Page and Column Floats
Page floats are almost identical to footnotes, but without the marker - content is moved to the top
or bottom of the current page. Column floats are the same, except the content is moved to the top
or bottom of the current column. BFO Publisher supports both by extending the CSS float property, using
a syntax based on https://www.w3.org/TR/css-page-floats-3/ but considerably simplified.
- float: top
-
Float the content to the top of the nearest multi-column container (the nearest item with a
column-widthorcolumn-countattribute other thanauto), or to the top of the page if the content is not within a column. - float: bottom
-
as
top, but floats the bottom of the column or page - float: page top
-
identical to
float: topexcept it always floats to the top of the page 1.4 - float: page bottom
-
as
page top, but floats to the bottom of the page 1.4
Index Generation
A special feature of BFO Publisher is the ability to generate a simple XML document containing
values calculated during the layout process. This can be used in a post-processing step, or it
can be included back into the document with <xi:include>
and a suitable stylesheet to create an index.
The generated XML file has the special URL about:index. It can be retrieved by calling
report.getResource("about:index") from the API, or by downloading the about-index.xml
file from the web-service after conversion has completed.
Creating the about:index file involves setting some custom CSS properties.
The syntax is very similar to the
bfo-tag
properties used for Tagged output, as both these
sets of properties are used to create an XML-like tag structure from the input XML and CSS.
It makes use of the <content-list> type definition from
https://drafts.csswg.org/css-content-3/#typedef-content-content-list
(although the leader() function is excluded, and the content() function
can also be used).
| Name |
-bfo-index |
| Value |
|
| Applies to |
all elements or pseudo-elements that are rendered in the output. |
| Inherited |
no |
| Description |
Controls the existance and format of this element in the generated index |
| Name |
-bfo-index-nnn |
| Value |
|
| Applies to |
any element or pseudo-element with |
| Inherited |
no |
| Description |
Sets the value of the nnn attribute on this element in the generated index |
Setting the -bfo-index attribute on an element will generate an element with that value
in the about:index document - if the element then contains other elements which also have
-bfo-index set, those elements will be properly nested.
If the <content-list> is set after the tag name, it will be used to populate the text content
of the node (text-content will precede all element children; mixing text and element children is
not recommended). And if a <content-list> is set on any -bfo-index-nnn property, it
will set the attribute nnn on the -bfo-index element to that content.
Some examples: to create an about:index file containing the page number for every element with
an id and noting the content and auto-generated heading number of every <h1>, you could do
something like this:
<style>
[id] {
-bfo-index: tag;
-bfo-index-id: attr(id);
-bfo-index-page: counter(page);
}
h1, h2 {
counter-increment: heading;
-bfo-index: "h" content(before) content(text);
-bfo-index-page: counter(page);
}
h1::before, h2::before {
content: counter(heading) ": ";
}
</style>
<section id="sect1">
<h1>first heading</h1>
...
<h2>second heading</h2>
</section>this would generate an about:index file like this:
<index:index xmlns:index="about:index">
<section id="sect1" page="1">
<h page="2">1: first heading</h>
<h page="5">2: second heading</h>
</section>
</index:index>The id attribute and generated page number for each item is included,
and the content() value used to copy the
content - including the generated content in the :before pseudo-node -
from the <h1> and <h2> elements to the generated tag.
Including the generated index
As well as downloading the about:index file after generation, it can also
be included into the source document before parsing completes. With
a few simple HTML attributes added to the document to create index entries,
an index can be generated as part of the conversion - all in a single pass.
This section bring together many of the features we’ve previously described - XInclude,
XSLT, Page counters and the -bfo-index properties decribed above.
And we’re now conceptually dealing with three XML documents:
-
the input XML, which will be annotated to create index entries
-
the
about:indexfile which those entries generate -
the XML file created by transforming
about:indexwith theorg.faceless.publisher.ext.IndexFilterstylesheet.
This stylesheet places requirements on on the about:index XML that need
to be met.
As a result, this chapter is necessarily more complicated than the others. We’ll first walk through a process of how you might do this, show the results, and then in the next sub-section we’ll go into detail of how it works.
An example generated index
The first step is to annotate our XML or HTML input to generate index entries. There are many ways you could do this; For now we’ll just describe the approach we took for the PDF version of this document, which involved setting one of three custom attributes on an HTML element to create an index entry.
Here’s the stylesheet we added to the file.
/* Set "data-index" attribute to create a single index entry for that item */
[data-index] {
-bfo-index: "entry";
-bfo-index-id: attr(id);
-bfo-index-term: attr(data-index);
-bfo-index-page: counter(-bfo-page-physical) " " counter(page, auto);
}
/* Set "data-index-range" attribute to create a "range" index entry
for that item, referencing all pages containing the element */
[data-index-range] {
-bfo-index: "entry";
-bfo-index-id: attr(id);
-bfo-index-term: attr(data-index-range);
-bfo-index-page: counter(-bfo-page-physical) " " counter(page, auto);
-bfo-index-to-page: counter(-bfo-page-physical-close) " " counter(-bfo-page-close, auto);
}
/* Set "data-index-xref" attribute to create a cross-reference entry which has no page */
[data-index-xref] {
-bfo-index: "entry";
-bfo-index-term: attr(data-index-xref);
}Check the Page counters section for details on those custom counter values.
To use these styles from within our source HTML, we set one of those attributes
on any element we want to index (that is not display:none).
The value of the attribute is the term - more
on that later, but at its simplest it’s just the phrase to index. In this example
we’re using a / character in the term to create a hierarchy: entry and sub-entry.
<section data-index-range="fruit">
<p>
...
text describing the <span data-index="fruit/apple">apple</span>
...
more text describing <span data-index="fruit/citrus fruit">citrus fruit</span>
...
an <span data-index-xref="fruit/orange -> fruit/citrus fruit">orange</span> is a type of
...
even more text describing <span data-index="fruit/citrus fruit">citrus fruit</span>
...
</p>
</section>the -bfo-index and -bfo-index-nnn properties have already been described, so if you’ve
been following along you’ll know that together, the stylesheet and HTML above
would generate something like the following about:index file:
<index:index xmlns="about:index">
<entry term="fruit/growing" page="5 5" to-page="15-15">
<entry term="fruit/apple" page="7"/>
<entry term="fruit/citrus fruit" page="9"/>
<entry term="fruit/orange -> fruit/citrus fruit"/>
</entry>
</index:index>We then need to include this XML back into the original source document, applying an appropriate stylesheet to convert it to an HTML index we can style.
Insert the following XML near the end of your input document - it must be after any
elements that would add to the index.
If you’re doing this in HTML rather than XML, you might
want to set the -bfo-ext-html-namespace environment property
to auto.
<xi:include
xmlns:xi="http://www.w3.org/2001/XInclude"
xmlns:bfo="http://bfo.com/ns/publisher"
bfo:xslt="classpath:org.faceless.publisher.ext.IndexFilter"
href="about:index"
/>This will include and transform the about:index file shown above with the
stylesheet at
org.faceless.publisher.ext.IndexFilter.
This is a class implementing XMLFilter rather than an XSLT stylesheet, as
the transform is a bit much for XSLT.
The transformed output looks something like this:
<section class="bfo-index-container">
<div class="bfo-index">
<div class="bfo-index-group" data-term="F">
<div class="bfo-index-heading" data-term="F">F</div>
<div class="bfo-index-entry" data-term="fruit">
<span class="bfo-index-term">fruit</span>
<span class="bfo-index-pages">
<a href="pdf:goto(5)">5</a>-<a href="pdf:goto(15)">15</a>
</span>
<div class="bfo-index-entry bfo-index-entry-final" data-term="apples">
<span class="bfo-index-term">apples</span>
<span class="bfo-index-pages">
<a href="pdf:goto(7)">7</a>
</span>
</div>
<div class="bfo-index-entry bfo-index-entry-final" data-term="citrus fruit">
<span class="bfo-index-term">citrus fruit</span>
<span class="bfo-index-pages">
<a href="pdf:goto(9)">9</a>,<a href="pdf:goto(12)">12</a>
</span>
</div>
<div class="bfo-index-entry bfo-index-entry-final" data-term="oranges">
<span class="bfo-index-term">oranges</span>
<span class="bfo-index-xref">fruit, citrus fruit</span>
</div>
</div>
</div>
</div>
</section>As these elements are now included into the source document, they can be styled in the normal way.
A default user-agent stylesheet is included as part of the index -
it’s in the Jar as org/faceless/publisher/data/index.css
and can be retrieved by calling
Report.getResource(URL2.parse("classpath:data/index.css")).
Here’s how the generated index looks, with the default styles.

Index file format details
The main aspect of this section is the transformer
org.faceless.publisher.ext.IndexFilter
and the format it expects, which we’ll call the BFO Publisher Index format. As the IndexFilter
is a class in the classpath, it has API documentation which will add to what’s described here.
The IndexFilter class has a convenient transform() method which can be used to quickly
transform an input XML to an output XML. It also has a main method which runs this transform
on System.in and writes to System.out, so you can run it from the command line for testing.
|
The XML format consists of any root element, containing multiple <entry> elements.
Each <entry> may contain other <entry> elements (nesting is ignored) or
<term> elements. All other elements are transparent to this transformation. The definitions are:
- <entry>
-
defines an entry in the index. Multiple entries can exist for a single term, they will be merged to one entry with multiple pages. The attributes are
- term
-
specifies the index term or terms. An index term is required, and may be set with the
termattribute, a<term>descendant of the<entry>or both. There are three aspects to each term: the term itself, plus optionally how the term is sorted and (if it’s a cross-reference) what it’s referencing. Thetermattribute is actually a list of terms, for when one<entry>needs to create multiple index entries. The term is parsed with special formatting rules, best demonstrated by example:- term="apples"
-
add an entry with the term "apples"
- term="fruit/apples"
-
add an entry with the term "fruit" and a sub-entry with the term "apples". The class, page number etc. apply to the sub-entry (apples) rather than the parent (fruit).
- term="α-particle { alpha-particle }"
-
add an entry with the term "α-particle" but sort it as if it were "alpha-particle"
- term="α{alpha}-particle"
-
exactly as the previous example.
- term="http:\/\/"
-
add an entry "http://" - the slash characters are escaped by prefixing with a backslash "\"
- term="malus domestica -> apple"
-
add an entry "malus domestica" which is a cross-reference to the entry "apple".
- term="rgb() // rgba()"
-
add two identical entries, "rgb()" and "rgba()", both of which will refer to the same
pageset on the entry. - term="rgba() -> rgb() // #number -> rgb()"
-
create two entries for "rgba()" and "#number", both of which are cross-references to the "rgb()" entry.
If a term creates a cross-reference but no
pageattribute is specified, a see style entry is created. If a term creates a cross-references and apageattribute is set see also style entry created instead. There is no limit to how deep terms can go, but we suggest no more than three. - page
-
the page the item is on. The format is an integer starting at 1, followed optionally by the formatted value of the page. For example
page="12",page="12 12"andpage="12 xii"all link to page 12, but the final version will format the number using lower-latin digits. If nopageattribute is specified, thetermattribute must create a cross-reference, otherwise the entry is ignored. - to-page
-
if the entry covers a range of pages, the
to-pageattribute specifies the last page of the range. The format is identical topage. - class
-
the optional class to apply to the term.
- page-class
-
the optional class to apply to the page-number.
- id
-
if specified, the generated hyperlink in the index will be to that item rather than to the numbered page.
- <term>
-
any
<term>child of an<entry>will have its text-content and anytermattribute merged into thetermattribute of the parent<entry>, first replacing any zero-length terms then being appended if no zero-length terms exist. Each of the following groups of XML constructions are all equivalent:<entry term="apples" /> <entry> <term term="apples"/> </entry> <entry> <term>apples</term> </entry><entry term="fruit/apples" /> <entry> <term>fruit</term> <term term="apples" /> </entry> <entry term="/apples"> <!-- note leading slash - first term is blank --> <term term="fruit"/> </entry> <entry term="fruit"> <term>apples</term> </entry>
The transform will convert this input XML into an output XML, an example of which was shown in the previous section. The output XML has the following structure.
-
A wrapper
<section>element with classbfo-index-container -
A single element with class
bfo-index -
One or more elements with class
bfo-index-group, one for each group. Groups depend on the language, but broadly there is one per letter. -
Each
bfo-index-groupcontains one element with classbfo-index-heading, then one or more elements with classbfo-index-entry. -
Each
bfo-index-headingelement contains a single element with classbfo-index-termcontaining the name of the group, eg "F". -
Each
bfo-index-entryelement contains a single element with classbfo-index-termcontaining the term. It also contains either:-
one element of class
bfo-index-pagescontaining the<a>elements hyperlinking to the page, and the page number text. -
zero or more elements of class
bfo-index-xref-also, for any see also cross-references that exist alongside the page number.
or
-
one or more elements of class
bfo-index-xref, for any see cross-references that exist without a page number.
-
This reference with the example from the previous section should give you everything you need to style the index if required.
Customizing the transformed index
The transform that is applied to the input XML has a few settings that can be modified.
-
subdivision- the token to split aterminto hierarchy. The default is "/" - as in the example"fruit/apples" -
division- the token to split aterminto more than one term. The default is "//", as in the example"rgb() // rgba()" -
xref- the token which identifies the start of a cross-reference in the term - the default is "->". -
sort- the token (or pair of tokens) which delimits an optional sort-value in a term. The default is "{ }" - it should be two terms separated by a space. -
comma- the output-token inserted between two unrelated page numbers. The default is ",", as in the output "5,9" -
dash- the output-token inserted between two ranged page numbers. The default is an n-dash, as in the output "5—9" -
separator- the output-token inserted between a term entry and sub-entry in a see or see also cross-reference. The default is ",", as in the output "see fruit, apples". -
symbol- the text to use for the group of entries that begin with a symbol character. The default is "Symbol".
Each of these can be set as attributes on the root element of the input XML, which requires a particular approach when it’s included with XInclude:
<xi:include
xmlns:xi="http://www.w3.org/2001/XInclude"
xmlns:bfo="http://bfo.com/ns/publisher"
xmlns:xila="http://www.w3.org/2001/XInclude/local-attributes"
bfo:xslt="classpath:org.faceless.publisher.ext.IndexFilter"
href="about:index"
xila:subdivision="|"
xila:division="||"
xila:symbol="Simbolos"
/>Alternatively they can be set as environment variables in the document
@bfo env {
bfo-ext-index-subdivision: "|";
bfo-ext-index-division: "||";
bfo-ext-index-symbol: "Simbolos";
}Finally, note that sorting is done with java.text.Collator. This requires
the language to be set correctly on the document.
Graph Library 1.3
With BFO’s Graph Library included in the Java CLASSPATH, BFO Publisher can embed graphs and charts directly into the output. This functionality is new in version 1.3.
The XML syntax for the Graph Library predates BFO Publisher, and has no knowledge of CSS. We’ve adapted the syntax so that attributes defined in the XML syntax can be set by CSS; specifically:
-
The
width,height,overflowfont-family,font-size,font-weight,padding-*CSS properties set the corresponding XML attributes -
The
colorCSS property sets thetextcolorXML attribute -
The
fill,stroke,stroke-widthandstroke-dasharrayCSS properties set thecolor,bordercolor,linethicknessanddashXML attributes
Here’s an XML example
<html xmlns="http://www.w3.org/1999/xhtml">
<head>
<style>
axesgraph {
display: block;
width: 300pt;
height: 300pt;
font: 12px sans-serif;
}
data[x="04-MAY-2005"] {
fill: red;
stroke: transparent;
}
</style>
</head>
<body>
<h1>A graph</h1>
<axesgraph xmlns="http://bfo.co.uk/ns/graph?version=2">
<label>My Graph</label>
<axis pos="bottom" type="date(dd-MMM-yyyy)" density="sparse" align="top left"/>
<axis pos="left" type="int" min="0" max="20"/>
<barseries name="Freestyle">
<data x="02-MAY-2005" y="10"/>
<data x="04-MAY-2005" y="12"/>
<data x="06-MAY-2005" y="8"/>
</barseries>
</axesgraph>
</body>
</html>Graph Library tags are identified by their namespace, so to use them in HTML requires
HTML Namespace Extensions.
Probably the easiest is to set the namespace for axesgraph, piegraph, and dialgraph
in advance, which means the tags can be specified as if they were normal HTML5 tags.
The sample example as above in HTML syntax would be:
<!DOCTYPE html>
<html>
<head>
<meta name="bfo-ext-html-namespace" content="axesgraph=http://bfo.co.uk/ns/graph?version=2 piegraph=http://bfo.co.uk/ns/graph?version=2 dialgraph=http://bfo.co.uk/ns/graph?version=2"></meta>
<style>
...
</style>
</head>
<body>
<h1>A graph</h1>
<axesgraph>
<label>My Graph</label>
<axis pos="bottom" type="date(dd-MMM-yyyy)" density="sparse" align="top left"></axis>
... content as for the XML example above - but remember, no self-closing tags! ...
</axesgraph>
</body>
</html>Factur-X 1.3
Factur-X (also known as ZUGFeRD) is a European initiative for electronic invoicing, primarily used in Germany and France. Technically, it’s nothing more than an XML file embedded in a PDF/A-3 document, so BFO Publisher can create Factur-X invoices very easily.
The steps below presume you already have the invoice data as an XML file; BFO Publisher doesn’t do any checks on the validity of this file, but it should comply with CII XML ("Cross Industry Invoice", more formally UN/CEFACT SCRDM CII D16B) : the the root element should be:
<rsm:CrossIndustryInvoice xmlns:rsm="urn:un:unece:uncefact:data:standard:CrossIndustryInvoice:100">To take a file like this and turn it into a Factur-X compliant invoice, there are several options.
Create HTML for the invoice manually, and store the invoice XML in an external file.
If you have code that generates the invoice XML from data from your database, an obvious option is also generate the HTML for the invoice from the same source. The basic format of any HTML file for conversion to a Factur-X invoice is as follows:
<html>
<head>
<meta name="bfo-pdf-profile" content="factur-x-basic">
<link rel="attachment/alternative" name="factur-x.xml" href="path/to/myinvoice.xml">
</head>
<body>
<h1>Invoice</h1>
...
</body>
</html>The only parts that need adding beyond a basic HTML file are
-
The
bfo-pdf-profilemeta key is set tofactur-x-basic,factur-x-extendedorfactur-x-en16931 -
The XML is attached using a
<link rel="attachment/alternative" name="factur-x.xml" …>
Create XHTML for the invoice manually, and store the invoice XML in the same file.
If you’re working with XHTML, it’s quite natural to include the Invoice XML data in the same
file. This is identical to the process above except the href attribute refers to a fragment URL -
the only requirement here is the link is used before the element it refers to.
If you’re doing this, you’re probably using XHTML rather than HTML:
<html xmlns="xmlns="http://www.w3.org/1999/xhtml">
<head>
<meta name="bfo-pdf-profile" content="factur-x-basic" />
<link rel="attachment/alternative" name="factur-x.xml" href="#factur-x" />
<rsm:CrossIndustryInvoice id="factur-x" xmlns:rsm="urn:un:unece:uncefact:data:standard:CrossIndustryInvoice:100">
...
</rsm:CrossIndustryInvoice>
</head>
<body>
<h1>Invoice</h1>
...
</body>
</html>Create HTML/XHTML for the invoice manually, and store the invoice XML in the same file, wrapped in a <script>
The above option requires an id attribute is set on the <rsm:CrossIndustryInvoice> element,
but if you don’t want to do this (or if you want to use HTML rather than XHTML) then
wrap the Invoice XML in a <script> element.
This works in HTML because the datamodel for <script> allows it to embed
just about anything;
it’s the recommended way to embed JSON-LD, RDF and other content without needing to escape it. If you’re
using XHTML then you still need to abide by the rules of XML, which typically means using a
<![CDATA[ … ]]> immediately inside the <script> to wrap the XML.
<html>
<head>
<meta name="bfo-pdf-profile" content="factur-x-basic" />
<link rel="attachment/alternative" name="factur-x.xml" href="#factur-x" />
<script type="text/xml" id="factur-x">
<rsm:CrossIndustryInvoice xmlns:rsm="urn:un:unece:uncefact:data:standard:CrossIndustryInvoice:100">
...
</rsm:CrossIndustryInvoice>
</script>
</head>
<body>
<h1>Invoice</h1>
...
</body>
</html>Use XSLT to convert the Invoice XML to XHTML
The most elegant solution uses an XSL stylesheet to generate the visual appearance of the invoice directly from the invoice XML.
A custom stylesheet may include the appropriate <link> and <meta> tags
to attach the Invoice XML and set the bfo-pdf-profile to the Factur-X profile.
The XML being attached is actually the source document itself, so the link tag should look like
this (the href "#" refers to the whole document).
<link rel="attachment/alternative" name="factur-x.xml" href="#"/>Generating a suitable XSL stylesheet is complex. BFO has generated an open-source XSLT stylesheet to demonstrate one way to do it, which is probably a useful starting point if you want to generate your own. These are published at https://github.com/bfocom/publisher-extra/tree/main/factur-x
Altnernatively, the XRechnung developers have published some open-source stylesheets to do this at
https://github.com/itplr-kosit/xrechnung-visualization which generate HTML from CII XML input
(the one with <rsm:CrossIndustryInvoice> as a root). They do this in two stages;
one XSL stylesheet convers from CII to an intermediate XML format, and a second XSL stylesheet
converts from this to HTML. Both stylesheets use XSLT 2.0, so you will need an XSLT2 processor.
We highly recommend adding Saxon to your CLASSPATH.
These stylesheets generate HTML that includes JavaScript and that is not designed for print layout,
so some work will be required to get useful output from these when used with BFO Publisher.
We’ll present here a worked example of how to do this with the BFO open-source stylesheets.
First, you’ll need a CII XML document to convert - if you don’t have one, there is a
sample included with that package as src/test/instances/wrong-date-with-text-uncefact.xml
The conversion requires a processing instructions is added to the XML; the most obvious way to do this is to edit the XML itself. Add the line shown below to the top of your XML file, ensuring you use the correct path to the XSL stylesheets. We’ve placed ours in the root folder of the downloaded package.
<?xml-stylesheet href="invoice.xsl"?>
<rsm:CrossIndustryInvoice xmlns:rsm="urn:un:unece:uncefact:data:standard:CrossIndustryInvoice:100">
...
</rsm:CrossIndustryInvoice>The <?xml-stylesheet?> line ensures the XML will be transformed by the specified styleheet before
it is processed by BFO Publisher. Try it now to convert the XML file to PDF; the output is
almost Factur-X compliant.
The problem (which we hinted at above) is that the embedded XML file now contains that processing
instruction. This situation is common enough that in BFO Publisher 1.4, you can add
add the bfo-no-processing-instructions parameter to the attachment type, and they will be removed
from the XML before it is attached.1.4
<link rel="attachment/alternative" type="text/xml;bfo-no-processing-instructions" name="factur-x.xml" href="#"/>Alternatively specify the processing instruction by way of the API or Web Service, whichever you’re using. So if using the API, you might do something like this:
import java.io.*;
import java.util.*;
import org.xml.sax.SAXException;
import javax.xml.parsers.ParserConfigurationException;
import org.faceless.publisher.ReportFactory;
import org.faceless.publisher.Report;
import org.faceless.publisher.output.ReportOutput;
import org.faceless.publisher.type.MediaType;
import org.faceless.publisher.type.ProcessingInstruction;
public class Test {
ReportFactory factory = new ReportFactory();
public void convert(File infile, File outfile) throws IOException, SAXException, ParserConfigurationException {
Report report = factory.createReport();
List<ProcessingInstruction> pi = report.getProcessingInstructions();
pi.add(new ProcessingInstruction("xml-stylesheet", "href=\"invoice.xsl\""));
ReportOutput output = factory.createReportOutput(MediaType.parse("application/pdf"));
report.setReportOutput(output);
report.load(infile);
report.parse();
FileOutputStream stream = new FileOutputStream(outfile);
output.write(stream);
stream.close();
}
}if using the Web Service you could send a request like this
{
"type": "convert",
"uri": "myinvoice.xml",
"processing_instructions": [
{"type":"xml-stylesheet", "data":"href=\"invoice.xsl\""}
],
"put": [
{"path": "myinvoice.xml", "content_type": "text/xml", "content": ... },
{"path": "invoice.xsl", "content_type": "application/xslt+xml", "content": ... },
{"path": "invoice.css", "content_type": "text/css", "content": ... },
...
]
}An even smarter solution would be to put the stylesheet the resources it refers to
in a shared folder to save uploading them every time.
See the extra-folders property in the Web Service documentation for details.
If you’re working with other XSL stylesheets intended for general HTML output,
chances are they will not set the correct <link> and <meta> tags in the HTML.
You can edit these in, of course, but if that’s not possible both these properties
can also be set the API or Web-Service.
To add the <link>, use a link processing instruction - see Linking Resources
for details on this custom BFO Publisher extension. And the bfo-pdf-profile
metadata can be set any number of ways, as it’s just an
Environment variable. It can be set with the environment
key to the Web-Service, or add it to the map returned by Report.getEnvironment()
if using the API.
What if my initial format is not CII XML?
Factur-X mandates CII XML as the XML format that is embedded, but it’s a bit unfriendly to work with.
If you have an initial XML format that can be transformed to CII XML using an XSL stylesheet, the transformed
XML can be embedded by using the bfo:xslt attribute on the <link>.
<!--
Use the approach shown in earlier examples to embed CII XML
-->
<html xmlns="xmlns="http://www.w3.org/1999/xhtml">
<link rel="attachment/alternative" name="factur-x.xml" href="cii.xml" />
...
</html>
<!--
Use this approach to transform another XML format to CII XML before embedding it
-->
<html xmlns="xmlns="http://www.w3.org/1999/xhtml" xmlns:bfo="https://bfo.com/ns/publisher">
<link rel="attachment/alternative" name="factur-x.xml" href="simple.xml" bfo:xslt="transform.xsl" />
...
</html>The XML syntax is shown, but remember with HTML that non-standard namespaces need special processing. See HTML Namespace Extensions for details.
This will also work with the XSLT-based approach to conversion shown above. The inital XML invoice
would be transformed to HTML with one stylesheet, and it would be converted to CII XML using a
different stylesheet before embedding.
If using a <?link?> processing
instruction to do this, the namespace requirement on the xslt "attribute" is dropped.
<?xml-stylesheet href="xsl/convert-to-html.xsl"?>
<?link rel="attachment/alternative" name="factur-x.xml" xslt="xsl/convert-to-cii.xsl" href="#"?>
<my-simple-invoice>
...
</my-simple-invoice>EMail to PDF 1.4
BFO Publisher has native support for converting RFC822 email to PDF, and
supplying an object of type message/rfc822 for conversion will create a
formatted PDF with key headers, the message body, and any attachments
embedded in the output. Of course there are many different ways to do this,
but the core process is just that: set the media type and supply the message.
Email messages are generally multipart messages and contain headers, an optional HTML body, an optional plain-text body, and zero or more other parts which may be inline (typically resources that are referenced from the HTML part) or attachments. There are plenty of variations within this this and many emails are still plain-text rather than multipart, but exceptions beyond that are now very rare. So this is the model we’ll use for email.
Already we can see there are several decisions to make when converting to PDF
-
How should headers be presented?
-
If HTML and plain-text bodies are present, should one or both be preserved?
-
Should attachments be included?
Rather than providing a prescriptive answer, BFO Publisher converts email to PDF in two steps: first it processes the email into a JSON representation containing the headers and URLs that can be used for the various email parts. In the second step that JSON object is applied to a template (see Templates), which converts it to HTML, and that HTML is then converted to PDF in the usual way. The template is responsible for how to format the headers, body and attachments; BFO Publisher currently ships with two templates, and custom ones may also be created if required.
| BFO Publisher includes an RFC822 parser and doesn’t require Java EE or Jakarta EE to parse email, although it can work with both those packages; see IMAP Integration |
Configuration options
Conversion from email to HTML requires a template as mentioned above, which is specified with environment properties.
| Name |
bfo-ext-mail |
| Value |
<template name or url> |
| Initial Value |
default |
| Description |
the name of a pre-defined configuration, or a URL of a ZMarker or Freemarker template |
The default templates shipping with BFO Publisher are as follows. Note the names are matched
case-insenstively and without punctuation, so EA-Mail-1s + PDF/A-3 and eamail1spdfa3 will give
the same results.
- default
-
The default template is used if this parameter is not specified. The PDF is created as a tagged PDF (not PDF/A), with the
To,From,SubjectandDatefields populated. On the same page immediately below the headers is the HTML body if available, or the plain-text body if not. If the email contains any attachments, they are added as "file annotations" to the PDF. "Attachments" means any non-multipart container parts withContent-disposition: attachmentsor that have a media type ofapplication/*(ensuring emails consisting of a single binary file type will format as an empty body with the file attached). PDF Metadata is the same as EA/Mail-1.0, without the conformance claims and the list of attachments. - ea-mail-1s + pdf-1
-
Generates a PDF matching the EA-PDF 1.0 "PDF/Mail-1s" profile and compliant with PDF/A-3a. The PDF is tagged and formatting is as for
defaultexcept headers, body and attachments are all on different pages. The raw email file is also attached. - ea-mail-1s + pdf-2
-
Generates a PDF matching the EA-PDF 1.0 "PDF/Mail-1s" profile and compliant with PDF/A-4f. The PDF is tagged and formatting is as for
defaultexcept headers, body and attachments are all on different pages. The raw email file is also attached. - ea-mail-1si + pdf-1
-
Generates a PDF matching the EA-PDF 1.0 "PDF/Mail-1si" profile and compliant with PDF/A-3u. The PDF is tagged and formatting is as for
defaultexcept headers, body and attachments are all on different pages. - ea-mail-1si + pdf-2
-
Generates a PDF matching the EA-PDF 1.0 "PDF/Mail-1si" profile and complaint with PDF/A-4. The PDF is tagged and formatting is as for
defaultexcept headers, body and attachments are all on different pages.
Concise naming isn’t a strong-point of the EA-PDF specification, but just remember there are
two variants for output (PDF/A-3a creates a PDF 1.7 file, and PDF/A-4f creates a PDF 2.0 file),
and a single email (the "s" in "mail-1s") can be isolated or non-isolated; isolated means the
raw message source is not attached to the file.
Isolated configurations are not suitable for creating PDFs as verifiable preservation assets;
Select a ea-mail-1s + pdf-n template for that purpose.
Any value other than the ones above will be treated as a URL of a template file, and several other properties can be used to control how the template is used:
| Name |
bfo-ext-mail-template-type |
| Value |
<media-type> |
| Description |
the format of the template, currently either |
| Name |
bfo-ext-mail-template-output-type |
| Value |
<media-type> |
| Initial-Value |
"text/html" |
| Description |
the media-type of the output of the template - set to |
Note that the environment variables must be set on the factory. It can not be set in a CSS
stylesheet or HTML file, for the obvious reason that this property determines which CSS and
HTML files to use. When using the API it must be added to
ReportFactory.getEnvironment(),
and when using the web-service it must be set in the env section:
#!/bin/sh
curl --request POST --header "Content-Type:application/json" ${BASEURL}/convert --data @- <<EOF
{
"redirect": false,
"env": {
"bfo-ext-mail": "ea-mail-1s pdf1"
},
"put": [
{
"path": "message.eml",
"content_type": "message/rfc822",
"content": …
}
]
}
EOFCustom templates
Custom templates can be used as well as the predefined templates if required - we strongly recommend
extracting one of the existing templates shipping from the Jar and modifying it (they are in the
org/faceless/publisher/data/mail/ folder of the Jar - both the default.ztl and eamail.ztl templates
use the ZTemplate processing language and output XML.
Any environment properties beginning with bfo-ext-mail- will be set in the env dictionary of the JSON
object supplied to the template, minus that prefix. This allows the template to select different output
options based on different input properties, and can also be used to substitute in dynamic values like
the current date/time. This approach is strongly recommended over creating a new template containing a
hard-coded date for each email, which will prevent caching from working.
See the BFO blog at https://bfo.com/blog/tags/eamail for articles on this topic.
IMAP Integration
If either Jakarta EE or Java EE are installed then BFO Publisher can also communicate
directly with an IMAP mail server, and can convert from
javax.mail.internet.MimeMessage or jakarta.mail.internet.MimeMessage
objects supplied to the
Report.load(source)
method. Publisher is compiled against both APIs, and if both are found will favor jakarta.mail.
The MailServerExtension is
a helper class to manage the connections to IMAP servers. There is no need to use this
class if IMAP connections are managed elsewhere, hoever it provides a convenient way to connect
with IMAP servers, with the configuration for each server entirely described in a
JSON object. See the API documentation for details and example usage. Email from
an IMAP server loaded by this class can also be accessed by supplying a URL with the imap
scheme as defined in RFC 5902.
API Usage
BFO Publisher is a Java API at heart, and can be easily embedded in any larger product to enable conversion. It’s built on the BFO PDF Library from https://bfo.com/products/pdf, which is included in the JAR.
Dependencies
There are three JAR files included with the product download - the two main ones are:
- bfopublisher.jar
-
Contains BFO Publisher, the BFO PDF Library (from https://bfo.com/products/pdf) and the open-source BFO JSON library from https://faceless2.github.io/json/.
- bfopublisher-bundle.jar
-
As
bfopublisher.jarbut also includeshtmlparser.jarand thenettyJAR listed below. This JAR alone can be used to convert HTML/XML to PDF and run the web service.
When running standlone, the bfopublisher-bundle.jar file is probably the easiest. If you want
to manage dependencies yourself then include the bfopublisher.jar in the CLASSPATH, along
with any JAR files listed below that are required.
| All the below JARs are optional. Conversion can run without them, although some functionality will not be available. |
- htmlparser-VERSION.jar
-
Available from https://about.validator.nu/htmlparser/ with more recent builds from https://mvnrepository.com/artifact/nu.validator/htmlparser, we’ve tested both the 1.4 version (from 2012) and recent nightly builds. We strongly recommend this is in the classpath - without it, conversion of HTML (as opposed to XHTML) will not work.
- netty-buffer-VERSION.jar
- netty-codec-VERSION.jar
- netty-common-VERSION.jar
- netty-handler-VERSION.jar
- netty-transport-VERSION.jar
-
These five JARs from the Netty project (https://netty.io) are required to use the web-service, but are otherwise optional. Version 4.1.73 or later is required.
- saxon-VERSION.jar
-
From https://www.saxonica.com/, the Saxonica JAR is recommended if XSLT transformation is used. We’ve tested with version 9.9he but any version should be fine as we (mostly) use the standard Java XSLT interface to communicate.
- xalan-VERSION.jar
-
From https://xml.apache.org/xalan-j/, Apache Xalan is an alternative for XSLT transformation. We’ve tested with version 2.7.2 but again, any version should be fine as we use the standard Java XSLT interface.
- zstd-jni-VERSION-PLATFORM.jar
-
From https://github.com/luben/zstd-jni - if available, HTTP connections can use Zstd compression
- lz4.jar
-
From https://github.com/lz4/lz4-java - if available, HTTP connections can use LZ4 compression
- jlessc-VERSION.jar
-
From https://github.com/i-net-software/jlessc - if in the classpath, stylesheets with a
relattribute ofstylesheet/lesswill be automatically converted to CSS - sass-embedded-host-VERSION.jar
- sass-embedded-protocol-VERSION.jar
- protobuf-java-VERSION.jar
-
From https://github.com/larsgrefer/dart-sass-java - if in the classpath, stylesheets with a
relattribute ofstylesheet/scsswill be automatically converted to CSS. - webp-imageio-core-VERSION.jar
-
From https://github.com/nintha/webp-imageio-core - if available, WEBP format images can be loaded.
- bfopdf-jj2000.jar
-
Included with the download package and also available at https://github.com/faceless2/jpeg2000, this JAR is required if JPEG2000 images need to be decompressed to bitmap. This happens when converting an HTML file referencing a JPEG2000 image bitmap, SVG, or PDF/A-1.
Getting started
| the API Documentation is included with this help and served by the embedded web-server, or is available from https://publisher.bfo.com/live/help/api. Only classes which are useful for end-users have been documented, so it won’t be too overwhelming |
Here’s a simple example
import java.io.*;
import org.xml.sax.SAXException;
import javax.xml.parsers.ParserConfigurationException;
import org.faceless.publisher.ReportFactory;
import org.faceless.publisher.Report;
import org.faceless.publisher.output.ReportOutput;
import org.faceless.publisher.type.MediaType;
public class Test {
ReportFactory factory = new ReportFactory();
public void convert(File infile, File outfile) throws IOException, SAXException, ParserConfigurationException {
Report report = factory.createReport();
ReportOutput output = factory.createReportOutput(MediaType.parse("application/pdf"));
report.setReportOutput(output);
report.load(infile);
report.parse();
FileOutputStream stream = new FileOutputStream(outfile);
output.write(stream);
stream.close();
}
}The conversion process usuaully goes like this:
-
Create a single
ReportFactoryobject, which is used for multiple conversions. Reusing it allows stylesheets, fonts, images etc. to be cached and shared - it will be faster. AReportFactorycan be shared across threads. -
Create a
Reportfor a single conversion by callingfactory.createReport() -
Create a
ReportOutputfor that conversion by callingfactory.createReportOutput()or simply instantiating the requiredReportOutputclass directly, e.g.new PDFReportOutput(). -
At a minimum call
report.setReportOutput(), then configure anything else that might be required before conversion. -
Call
report.load(source)to load the report. The source can be anything we can realistically convert to a byte stream -java.io.File,java.net.URL,java.io.InputStream,byte[]ororg.xml.sax.InputSourceto name a few. -
Call
report.parse(). This runs the conversion and writes the report to theReportOutput -
When complete, call
output.write()or retrieve the generated report by calling a method on the subclass, egPDFReportOutput.getPDF()
Exploring the API
Customizing: properties, stylesheets, fonts, resources
We’ve claimed BFO Publisher is entirely configurable with environment properties, so you might expect these to be easy to set throught the API.
For example, to force every PDF conversion to generate PDF/A-3 rather than regular PDF:
ReportFactory factory = new ReportFactory();
factory.getEnvironment().put("bfo-pdf-profile", "PDF/A-3a");Every Report created from this ReportFactory now has this environment property set. Or it can also be done on a per-report basis:
ReportFactory factory = new ReportFactory();
Report report = factory.createReport();
report.getEnvironment().put("bfo-pdf-profile", "PDF/A-3a");Adding stylesheets can be done in the same way, by calling either the
ReportFactory.getUserStylesheets()
or
Report.getUserStylesheets()
methods as appropriate - new URLs can be added to the returned list. In particular
the Util.createDataURL()
method is useful for creating a Stylesheet from text.
For example, to reproduce the same functionality as the
the getEnvironment()
example shown above with a stylesheet:
String stylesheet = "@bfo env { bfo-pdf-profile: \"PDF/A-3a\"; }";
URL2 uri = Util.createDataURL(MediaType.parse("text/css"), stylesheet);
factory.getUserStylesheets().add(uri);This approach can also be used to preconfigure BFO Publisher with a stylesheet referring to locally stored fonts: unlike your web browser, BFO Publisher does not make use of the system font directory, and we ship with a very limited selection.
A common setup would be a directory containing some of the Noto Fonts. Simply download the fonts you want into a directory, then:
reportFactory.getUserStylesheets().add(URL2.parse("fonts:/path/to/fontdirectory"));How does this work? BFO Publisher has a special handler for the URL scheme fonts - it’s similar to a
file URL but always results in a CSS file describing the font(s) at that path. You can point it
at a single font file or a directory, in which case it will recursively scan the directory for font files and
generate a CSS file for them all. It will even set up a watch on that folder, so any fonts that are added or
deleted will be automatically included when the URL is requested - making it suitable for long-running instances
of a BFO Publisher web-service.
If you want to see how this works, the code below shows how to request the content of that URL so you can see it
yourself. You can even re-add this as a data: URL using the approach shown in the previous example.
ReportFactory factory = new ReportFactory();
Report report = factory.createReport();
Blob blob = report.getResource(URL2.parse("fonts:/path/to/fontdirectory"));
System.out.println(blob.getString()); // Print the generated CSS
URL2 uri = Util.createDataURL(blob);
reportFactory.getUserStylesheets().add(uri);This approach is absolutely fine to use if you prefer, although of course the CSS is fixed and will not reflect any changes in the directory.
The code above demonstrates the
Report.getResource() method,
which can be used to retrieve objects from a URL exactly as the Report would do while parsing. As well
as being useful for debugging - you can see exactly what data is being loaded - it allow you to
retrieve the about:index file created during Index Generation. This must be done after the parse() method.
Report report = factory.createReport();
report.setReportOutput(new PDFReportOutput());
report.load(inputsource);
report.parse();
Blob blob = report.getResource(URL2.parse("about:index"));
System.out.println(blob.getString()); // This is the generated index as an XML file.Customizing: extensions
The ReportFactory.getReportFactoryExtensions()
method can be used to retrieve a list of
ReportFactoryExtension
objects which will be used to create the Reports. Several extensions are included by default, all of which will be instances
of the various classes in the org.faceless.publisher.ext package.
The API documents for those classes detail how to configure each of them, and the list can be modified to add new extensions if required.
For example, the
MailServerExtension
can be added to allow email to be retrieved from an IMAP server and converted to PDF.
Here’s an example showing how to do this from GMail - a more complete version and an
explanation of how it works is given in the API docs for that class.
ReportFactory factory = new ReportFactory();
MailServerExtension ext = new MailServerExtension(factory);
factory.getReportFactoryExtensions().add(ext);
// Configure the MailServer extension to work with GMail
MailServerExtension.GMailHelper gmail = new MailServerExtension.GMailHelper();
gmail.setEmail(username);
gmail.setClientId("NNNNN.apps.googleusercontent.com");
gmail.setClientSecret("NNNNN");
gmail.setRedirectURI("http://127.0.0.1:8000/oauth");
Json json = gmail.create());
URL2 uri = ext.createStore(json);
Store store = ext.getStore(uri);
// We are connected to the server - retrieve a javax.mail.Message and load it
Folder folder = store.getFolder(foldername);
if (!folder.isOpen()) {
folder.open(Folder.READ_ONLY);
}
Message message = folder.getMessage(num);
Report report = factory.createReport();
ReportOutput output = factory.createReportOutput(MediaType.parse("application/pdf"));
report.setOutput(output);
report.load(message);
report.parse();
output.write(new FileOutputStream("email.pdf"));Customizing: URL Processors
Any resource loaded from a URL will be processed by all the
URLConnectionProcesser
object registered with the ReportFactory, which can configure authentication, SSL parameters
or similar. As with the previous section, URL processors can be retrieved by calling
ReportFactory.getURLConnectionProcessors()
which returns a list preconfigured with defaults; each item in the list can be removed
or altered as its API allows.
For example, to load client certificates for use with all HTTPS requests made by BFO Publisher
ReportFactory factory = new ReportFactory();
URL2 url = URL2.parse("file:/path/to/clientkeystore.jks");
char[] password = "secret".toCharArray();
SSLURLConnectionProcessor processor = new SSLURLConnectionProcessor(null, url, password, factory);
factory.getURLConnectionProcessors().add(processor);The available subclasses of
URLConnectionProcesser
will be clear from the API documentation - each of them details how they can be used to
alter any network connection made by BFO Publisher.
Web Service
You’re running BFO Publisher version ${VERSION} as a live web service
with the prefix ${BASEPATH}/. This section of the documentation
is interactive - it will guide you through the process of generating a PDF.
BFO Publisher can be run as a web service.
This section describes the service: if you were reading it as part of an installed
copy of BFO Publisher it would be interactive, allowing you to test the
web service in real-time.
So we recommend you download BFO Publisher and view this content from there.
Until them, we’ll use http://example.com to represent the path to the service.
| see https://github.com/bfocom/publisher-extra for APIs that work with the web-service |
Getting started with HTTP, JSON and CBOR
HTTP forms
Let’s start with a trivial example. Here’s a form field - type some HTML into it and click convert. The PDF will be loaded in this window, just click the back button when you’re done.
Now tick ← to request the PDF is returned as a redirect rather than immediately. Then click convert again.
When you click convert a request is made to ${BASEURL}/convert with the following fields:
-
put.0.content- the content of your field -
put.0.path- the valuefile.html -
redirect- true if the checkbox is ticked, false otherwise.
The request looks like this:
POST ${BASEPATH}/convert HTTP/1.1
Content-Type: application/x-url-form-encoded
redirect=true&put.0.path=file.html&put.0.content=…and when redirect=true, the response from the Publisher web service looks like this:
HTTP/1.1 200 OK
Content-Type: application/json
{"ok":true,"paths":{
"base":"store/7W4ABW2UySxh1ra4",
"log":"store/7W4ABW2UySxh1ra4/log.txt",
"output":"store/7W4ABW2UySxh1ra4/output.pdf"
}}Every response will include a boolean ok value (which is false if something went wrong).
Assuming it’s true, the response from /convert contains paths for at least the logs and
the generated output file (they’re relative to the current request).
To retrieve the output, make a standard GET request:
GET ${BASEPATH}/store/7W4ABW2UySxh1ra4/output.pdf HTTP/1.1As well as regular HTTP POST, it’s possible to
use multipart/form-data to upload files for conversion.
Click this button to select a file then click convert - as before,
the PDF will display in this window so just click the back button when you’re done.
With multipart/form-data the request looks like this:
POST ${BASEPATH}/convert HTTP/1.1
Content-Type: multipart/form-data;boundary=-----ZdboxU5pTD41YBew
-----ZdboxU5pTD41YBew
Content-Disposition: form-data; name="put.0"; filename="file.html"
Content-Type: text/html
..
-----ZdboxU5pTD41YBew--and the response will be the same as the response above. The file to convert is specified as put.0,
and any resources that may be needed by that file for conversion (stylesheets, images etc)
may be sent as put.1, put.2 and so on.
You can easily convert files this way using the curl command-line tool -
assuming the file to convert is file.html:
curl --form redirect=true --form put.0=@file.html --form put.1=@logo.png \
${BASEURL}/convertJSON/CBOR
In both the examples above we’ve used HTML forms to upload data, but we recommend JSON (RFC8259) or ideally CBOR (RFC8949). HTTP uploads are converted to one of these before processing - both of the above requests are essentially identical to this:
curl --request POST --header "Content-Type:application/json" ${BASEURL}/convert --data @- <<EOF
{
"redirect": true,
"put": [
{
"path": "file.html",
"content_type": "text/html",
"content": …
},
{
"path": "logo.png",
"content_type": "image/png",
"content": …
}
]
}
EOFPOST ${BASEPATH}/convert HTTP/1.1
Content-Type: application/json
{
"redirect": true,
"put": [
{
"path": "file.html",
"content_type": "text/html",
"content": …
},
{
"path": "logo.png",
"content_type": "image/png",
"content": …
}
]
}It should now be clear why the HTML form fields were called put.0.path or put.0
- they’re mapped to the corresponding property paths in the JSON object.
Files sent as part of an application/json encoded message
may be Base64 encoded - the decoder will try that first, falling back
to plain UTF-8 if Base64 decoding fails.
But by far the best solution is to use application/cbor as the Content-Type and
encode the JSON structure as CBOR.
This is faster and more compact than JSON,
and as it contains a native byte-buffer type no Base64 encoding is required.
| The Web Service always uses the URL-and-filename-safe variation of Base64 as defined in RFC4648 |
From now on all examples will be formatted as JSON for clarity, but CBOR is the recommended encoding for all communication with BFO Publisher. If a request is submitted in CBOR the response will also be CBOR. In all other cases, the response will be JSON. There are CBOR libraries for most languages; if you’re using Java we recommend https://github.com/faceless2/json, which is included as part of BFO Publisher.
The Store
The examples above included a put array, so called because they PUT a
file to the Store before conversion.
The Store is essentially a simple virtual filesystem -
files are first uploaded to it, then BFO Publisher retrieves them for
conversion before writing the results back to the Store.
They’re then retrieved with a GET, and eventually deleted with DELETE.
The URL for the store looks like ${BASEURL}/store
Files must be stored in a folder - generally (but not necessarily) a conversion
will be scoped to a single folder.
In the examples above the folder was created automatically, but if you prefer a
CRUD interface to upload
you can do that too.
Pick a random folder name (no slashes, spaces or special characters),
then upload the file - for example, with this curl command the following HTTP request
would be sent:
curl --header "Content-Type:text/html" --upload-file file.html \
${BASEURL}/store/7W4ABW2UySxh1ra4/file.htmlPUT ${BASEPATH}/store/7W4ABW2UySxh1ra4/file.html HTTP/1.1
Content-Type: text/html
…Files cannot be overwritten: if you need to, you must delete them first. Although a folder name must use a limited range of characters (see below) there are no restrictions on the path within that folder.
Once uploaded, you can run the conversion by specifying the folder to write the output to
and the URL of the file to convert with the url property.
URLs may be absolute or relative; relative URLs are resolved against the folder so
- as we want to refer to the existing folder we created with the previous upload -
we set this with the folder property.
POST ${BASEPATH}/convert HTTP/1.1
Content-Type: application/json
{"redirect":true, "folder":"7W4ABW2UySxh1ra4", "url":"file.html"}A standard HTTP GET can be used to retrieve any file. The directory listing of files in a folder can be retrieved by requesting the folder path:
GET ${BASEPATH}/store/7W4ABW2UySxh1ra4 HTTP/1.1HTTP/1.1 200 OK
Content-Type: application/json
[
{
"path": "log.txt",
"length": 3922,
"grants": { "all": [ "" ] },
"expiry": 604800000
}, {
"path": "file.html",
"length": 29
"content_type": "text/html",
"grants": { "all": [ "" ] },
"expiry": 604800000,
}, {
"path": "output.pdf",
"length": 4033
"content_type": "application/pdf",
"ok": true,
"grants": { "all": [ "" ] },
"expiry": 604800000,
}
]It’s possible to delete an individual file in the folder - or the entire folder - with an HTTP DELETE
curl --request DELETE ${BASEPATH}/store/7W4ABW2UySxh1ra4DELETE ${BASEPATH}/store/7W4ABW2UySxh1ra4 HTTP/1.1Deleting the folder or the output file within a folder will interrupt any conversion that’s current running.
And finally, because the CRUD interface can be a little clumsy
- particularly when using PUT to upload a file -
it’s possible to do all these operations with a POST of application/json
or application/cbor to the /store URL. Both get and delete require
only the path property, whereas put takes the other properties defined
for the put array specified to /convert. Here are some equivalents of the
above examples
Equivalent to GET ${BASEPATH}/store/7W4ABW2UySxh1ra4/output.pdf:
POST ${BASEPATH}/store HTTP/1.1
Content-Type: application/json
{"type":"get", "path":"7W4ABW2UySxh1ra4/output.pdf"}Equivalent to DELETE ${BASEPATH}/store/7W4ABW2UySxh1ra4:
POST ${BASEPATH}/store HTTP/1.1
Content-Type: application/json
{"type":"delete", "path":"7W4ABW2UySxh1ra4"}Equivalent to PUT ${BASEPATH}/store/7W4ABW2UySxh1ra4/file.html
POST ${BASEPATH}/store HTTP/1.1
Content-Type: application/json
{
"type": "put",
"content_type": "text/html",
"path": "7W4ABW2UySxh1ra4/file.html",
"content": …
}| see get (request), put (request) and delete (request) |
Some other things to note about the Store:
-
Uploads in all formats are streamed rather than decoded in memory. If you want to upload a 10GB file, it will be read from the stream (raw, CBOR, JSON or HTML encoded) and passed directly to the underlying Store, the default implementation of which will write it directly to disk.
-
If a Content-Type is not specified it will be sniffed from the data, which is necessarily imperfect. To be certain, always specify the type yourself.
-
Any undeleted files and folders will eventually expire some time after their last access, and be deleted automatically. Details on this are in the Configuration section.
-
Retrieving a file that hasn’t yet been created - for example, retrieving the
outputpath while the conversion is still running - returns immediately with HTTP code 202. Retrieving an output path if conversion failed will return HTTP code 500; thelogspath will provide detail. -
Retrieving the
logspath before conversion completes will return the existing log data and keep the connection open, with new log messages being streamed as they’re available. When conversion completes the connection is closed. -
The default FileStore implementation will checksum uploads and de-duplicate them on disk automatically, so uploading a file multiple times will not increase disk space (although of course it will increase network traffic).
Administration
The BFO Publisher web service is designed to be completely configured remotely, which allows identical instances to be deployed from a single virtual-machine image. The following administration tasks can be run:
Pause, Resume and Shutdown
The BFO Publisher web service can be paused at any point - new jobs will be accepted but not started, although running jobs will continue. Resuming will enqueue any jobs that were queued. Both are simple GET requests and take no parameters
Shutdown will pause BFO Publisher, wait for any running jobs to complete, then shut-down the server. If no jobs are running the server is shut-down immediately so no response is typically received.
GET ${BASEPATH}/admin/pause HTTP/1.1GET ${BASEPATH}/admin/resume HTTP/1.1HTTP/1.1 200 OK
Content-Type: application/json
{"ok":true, "message": "Resumed"}GET ${BASEPATH}/admin/shutdown HTTP/1.1Status
The internal status of the BFO Publisher web service can be retrieved by calling
/status or /admin/status (the latter gives detail on authorization keys,
so would typically be restricted - see Access Control).
As above, this is a simple GET request and takes no parameters
GET ${BASEPATH}/admin/status HTTP/1.1HTTP/1.1 200 OK
Content-Type: application/json
{
"class": "ServiceEngine",
"version": "work-42074M-20220113T010928",
"secure_mode": true,
"started": 1642036172188,
"paused": false,
"stats": {
"num_queued": 0,
"num_running": 0,
"max_queued": 0,
"max_running": 0,
"jobcount": {
"started": 0,
"cancelled": 0,
"completed": 0,
"failed": 0
}
},
"max_threads": 10,
"max_queue_size": 50,
"max_buffer_size": 1048576,
"authorities": [
{
"key": "none",
"grants": [ "*" ]
}
],
"egress_filter": "trustworthy or internet",
"url_processors": [
{
"type": "ssl-default"
}
],
"store": {
"classname": "org.faceless.publisher.web.FileStore",
"default_expiry": 604800000,
"max_expiry": 9223372036854776000
},
"cache_size": 200,
"ok": true
}Configuration
Configuration of the web service is done by a POST call to /admin/configure.
Configuration can only be performed
when no jobs are running - an error will be returned if that’s not
the case when /admin/configure is called. The engine can be paused and
any existing jobs allowed to complete before trying again.
The value supplied to /admin/configure is a JSON object, with the
keys listed at admin/configure (request).
All are optional: specified keys will completely replace any existing value.
Unspecified keys will remain unchanged, and all properties can be changed
while the server is running but paused;
so certificates on a long-running instance can be updated if required.
Access Control
By default the web service requires no authentication for any action - anonymous
users can perform any action, such as /convert or /admin/configure. In many
cases an administrator would want to place some limits on some of these.
The ability to perform any particular action on the web service is called a Grant. One or more Authorities can be set on the web service, each of which can approve a range of Grant actions as requested by the user. The web service uses Java Web Tokens (JWT, RFC7519) as a way of requesting these grants, very similar to the approach used with OAuth2.
Let’s start with the initial configuration. An excerpt from the /admin/status of a new
instance of the web service shows one Authority:
"authorities": [
{
"key": "none",
"origin": "*",
"grants": [ "**" ]
}
]The key value shows that no key is required - it authorizes anonymous access from any origin -
and that it will approve any grant. A ** matches any path and a * matches any path segment
(segments are divided with /). Any HTTP or WebSocket requests may include up to the default amount
of data, which is set with the max_buffer_size configuration property.
Let’s remove this Authority and replace it with two more - one that allows everything, and
one that disallows admin rights. For this we’ll need two generate two JSON Web Keys (JWK).
The easiest way to do this is at https://mkjwk.org and create two symmetric keys (oct in JWK
terminology) using the HS256 algorithm - call one admin and one user. Here’s what we generated:
{
"kty": "oct",
"kid": "admin",
"k": "MbDPJl_WUCDe0HI5ag-czbCXK0_X5iOikg_0GQfTN7IHcLsbsLbiCN2TeCsryKUzgc6aw9kI5vHR0-3BsfyAZwLkJmPnawRwJ0UV8aOspmZlYteWFf7YO3kM1szH6k6C6FwOifLnWreSiu8gFuW7e78aYQPHWQKhhuFcC6oBaXNhYm-ghZrZXA082c-xiJWD2KAJhJGJW2nEHY0NDm9Ae1ZAz7MiKZSDvoDoCViCqCdpznqP_gmniGKSTsXDyW5YcxraMvgwEUgvSRdPovuaKR6cPkXFF8XjL8zRjIqDjlCYYYHZPg_99__HBU9kOKBEXiqI20rXyofuuZ1Du2hhFw",
"alg": "HS256"
}
{
"kty": "oct",
"kid": "user",
"k": "xqF2PECEf9lzb-B2FOEM6L5SpQRbZHza5_IPAoae-d8AvBDNxb2nd6GhUzKLM61pXsNObJZoUc28Vcihgm3sDsH5Qu-uNGJzjOfz-w0R17qNVZCcUsFdGSxzkbHxUAdvN_rT5pU_9EapIuuEtaaaG8KSD1aenXlBpxxEfaKkGDvqeiYZjnkCx-qX5cFSXTlMo-mVxF8bdT4v9mzR13yIC1BAbexDep4E1Z5vhxCsQujpd1M2Wge20LXuAT4tPmPo86WqkTxPU_SLUAT1fvNUi1vUM0oUrQYTT6wocBX3fPktpqQ8VTUcx2rotNFiOFpMqhwxZKZoVg_A5A5bWxWRVg",
"alg": "HS256"
}Now we need to set those keys as Authorities on the web service. The first key, admin, we
will allow to approve all grants. The second key user can approve only non-admin
grants. The grants largely correspond to the actions defined in the web service, and are
currently:
http |
Access the web service over HTTP (either this or |
|---|---|
ws |
Access the web service over WebSockets |
get |
Call the |
put |
Call the |
delete |
Call the |
convert |
Call the |
proxy |
Call the |
status |
Retrieve the status of BFO Publisher, excluding any security-related properties |
admin/pause |
Pause the BFO Publisher service |
admin/resume |
Resume the BFO Publisher service |
admin/shutdown |
Shut down the BFO Publisher service, completing all running tasks first |
admin/status |
Retrieve the status of BFO Publisher, including any security-related properties |
admin/configure |
Configure BFO Publisher |
admin/trusted |
Mark a resource added to the store as a trusted resource |
bearer/nnn |
Access a file in the Store created by bearer token nnn (see Permissions) |
So to run all "non-admin" actions over HTTP or WebSockets, a user would need to be granted
["http", "ws", "get", "put", "delete", "convert"] - or, to match any non-admin actions,
you can use the grant ["*"].
POST the following message to admin/configure.
POST ${BASEPATH}/admin/configure HTTP/1.1
Content-Type: application/json
{
"authorities": [
{
"key": {
"kty": "oct",
"kid": "admin",
"k": "MbDPJl_WUCDe0HI5ag-czbCXK0_X5iOikg_0GQfTN7IHcLsbsLbiCN2TeCsryKUzgc6aw9kI5vHR0-3BsfyAZwLkJmPnawRwJ0UV8aOspmZlYteWFf7YO3kM1szH6k6C6FwOifLnWreSiu8gFuW7e78aYQPHWQKhhuFcC6oBaXNhYm-ghZrZXA082c-xiJWD2KAJhJGJW2nEHY0NDm9Ae1ZAz7MiKZSDvoDoCViCqCdpznqP_gmniGKSTsXDyW5YcxraMvgwEUgvSRdPovuaKR6cPkXFF8XjL8zRjIqDjlCYYYHZPg_99__HBU9kOKBEXiqI20rXyofuuZ1Du2hhFw",
"alg": "HS256"
},
"grants": [ "**" ]
},
{
"key": {
"kty": "oct",
"kid": "user",
"k": "xqF2PECEf9lzb-B2FOEM6L5SpQRbZHza5_IPAoae-d8AvBDNxb2nd6GhUzKLM61pXsNObJZoUc28Vcihgm3sDsH5Qu-uNGJzjOfz-w0R17qNVZCcUsFdGSxzkbHxUAdvN_rT5pU_9EapIuuEtaaaG8KSD1aenXlBpxxEfaKkGDvqeiYZjnkCx-qX5cFSXTlMo-mVxF8bdT4v9mzR13yIC1BAbexDep4E1Z5vhxCsQujpd1M2Wge20LXuAT4tPmPo86WqkTxPU_SLUAT1fvNUi1vUM0oUrQYTT6wocBX3fPktpqQ8VTUcx2rotNFiOFpMqhwxZKZoVg_A5A5bWxWRVg",
"alg": "HS256"
},
"grants": [ "*" ]
}
]
}HTTP/1.1 200 OK
Content-Type: application/json
{"ok":true,"code":200,"message":"Engine updated"}The previous Authority that granted anonymous access has been replaced by these two new Authorities. We can see the effect of this immediately:
GET ${BASEPATH}/admin/status HTTP/1.1HTTP/1.1 401 Unauthorized
Content-Type: application/json
{"ok":false,"message":"Unauthorized"}To access the service now, a JSON Web Token must be generated and signed by one of the keys above.
We can do this online at https://jwt.io. Copy the value of the user key into box for the secret key
on that website, and tick secret key base64 encoded. Then enter the following into the payload box:
{
"name": "BFO Publisher User",
}
Or if you’d prefer to do this with an API, here’s how to use our open-source JWT library at https://github.com/faceless2/json:
import com.bfo.json.*;
public class MakeJWT {
public static void main(String[] args) throws Exception {
JWK userkey = new JWK(Json.read("{ \"kty\": \"oct\", \"kid\": \"user\", \"k\": \"xqF2PECEf9lzb-B2FOEM6L5SpQRbZHza5_IPAoae-d8AvBDNxb2nd6GhUzKLM61pXsNObJZoUc28Vcihgm3sDsH5Qu-uNGJzjOfz-w0R17qNVZCcUsFdGSxzkbHxUAdvN_rT5pU_9EapIuuEtaaaG8KSD1aenXlBpxxEfaKkGDvqeiYZjnkCx-qX5cFSXTlMo-mVxF8bdT4v9mzR13yIC1BAbexDep4E1Z5vhxCsQujpd1M2Wge20LXuAT4tPmPo86WqkTxPU_SLUAT1fvNUi1vUM0oUrQYTT6wocBX3fPktpqQ8VTUcx2rotNFiOFpMqhwxZKZoVg_A5A5bWxWRVg\", \"alg\": \"HS256\" }"));
JWT jwt = new JWT();
jwt.getPayload().put("name", "BFO Publisher User");
jwt.sign(userkey.getSecretKey(), "HS256");
System.out.println(jwt);
}
}The generated JWT is passed in as a "Bearer Authorization" to the web service, exactly as it would be with OAuth 2.0
POST ${BASEPATH}/convert HTTP/1.1
Authorization: Bearer eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJuYW1lIjoiQkZPIFB1Ymxpc2hlciBVc2VyIiwiZ3JhbnRzIjpbImh0dHAiLCJ3cyIsImNvbnZlcnQiLCJnZXQiLCJwdXQiLCJkZWxldGUiXX0.xL0Pk5FPnGbWiiFG_3ICLYbnVpcn-ZZ_0jFUcoRQBYc
Content-Type: application/json
{"url": "https://bfo.com"}That’s the basic flow of Authentication, so now we can go into a bit more detail.
-
A request to the web service will be matched against each Authority in sequence. Any authority that signed the key can approve any of the requested
grantsassociated with it, and authorization can be granted by more than one Authority - the approved set of grants is the union of all that match. Likewise, themax-buffer-sizefor a user is the maximum of themax-buffer-sizefor each matching Authority. -
Anonymous access to the web service is allowed by an authority with a
keyofnone. This will match any request (with or without aBearertoken). If this Authority exists its grants will be merged with any grants from other Authorities that match the supplied JWT. -
HTTP CORS (Cross-Origin Resource Sharing) restrictions are supported by setting the
originvalue on an authority. This may be"*"for any origin (the default), a URL (no path should be specified) or a list of URLs. If anOriginheader is sent with the HTTP request it must match this value (for WebSockets, theOriginheader of the initial connection is used). TheOriginheader is set by web-browsers when requesting a URL from JavaScript, but is not normally set by non-browser clients, and is not set for the default Content-Type (see thesimple_apiconfiguration option for more detail). CORS support is new in release 1.4 1.4 -
The
*symbol can be used in an Authoritiesgrantsto match any character other than/, and the**symbol matches any character including/. So for example,-
grants: [ "*" ]matchesgetbut notadmin/pause -
grants: [ "admin/*" ]matchesadmin/pausebut notget -
grants: [ "*", "admin/*"]orgrants: [ "**" ]would match both (the second one matches everything). -
grants: [ "bearer/*" ]matches any Bearer token - this allows downloading or deleting files from the Store created by other users.
-
-
Any properties (claims, in the language of JWT) can be set in the payload of the JWT, but only the
nbfandexpproperties are recognised.nbfandexpstand for not-before time and expiry time, and are standard JWT properties to limit the validity of the token - they are both seconds since the UNIX epoch. Thenameproperty, if set, will be used to identify a JWT when logging. -
Any algorithm defined in the JWT core specification can be used - we’ve demonstrated the shared key approach above, but public/private RSA or Elliptic-Curve keys can be used as well.
-
Finally, although it’s best practice to generate a unique JWT for each user, this might not always be practical. For validation purposes the JWT supplied in the
Authorizationheader will ignore anything following a trailing#- soAuthorization: Bearer eyJhBG…RQBYc#my-unique-fragmentwould work in the example above.
Finally there are two other key aspects of an Authenticated workflow that do not apply to an anonymous workflow.
Permissions
Any file stored in the Store, whether uploaded by a user or generated by convert, is stored with a set
of grants determining which users can GET or DELETE the file. As discussed above, a grant is part of
the authorization process, and custom grants can be added to any authorization - for example,
"grants": [ "http", "ws", "convert", "get", "put", "delete", "team-b" ] would grant a user access to
all the normal grants required for creating PDFs, plus the team-b grant. The set of grants for each
user includes any that are authorized by an authority, plus any that are specified as part of their JWT.
By default, the only grant attached to any file is the Bearer token that created it. In the last example above, the file is stored with the following metadata:
{
"grants": {
"all":[
"bearer/eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJuYW1lIjoiQkZPIFB1Ymxpc2hlciBVc2VyIiwiZ3JhbnRzIjpbImh0dHAiLCJ3cyIsImNvbnZlcnQiLCJnZXQiLCJwdXQiLCJkZWxldGUiXX0.xL0Pk5FPnGbWiiFG_3ICLYbnVpcn-ZZ_0jFUcoRQBYc"
]
}
}Any user presenting that Bearer token will be able to GET or DELETE the file - to use an analogy with UNIX
file permissions, the file is stored with permission 0600, and it can be accessed only by the user that
created it.
Allowing access to other users means specifying additional grants when the file is created - grants exist
for get to allow downloading, delete to allow deletion and any to allow both.
They can be specified when converting to control the grants required for the generated file.
The below JSON could be passed to /convert to allow any user to download
the generated file, but only users with the team-b grant to delete it.
{"url": "http://bfo.com", "grants": { "get": [ "*" ], "delete": [ "team-b" ] } }They can be specified when uploading files as part of a convert in a similar way.
{
"url": "http://bfo.com",
"put": [
{
"path": "style.css",
"content_type": "text/css",
"content": "...",
"grants": { "any": [ "*" ] }
}
]
}But when uploading files to the store with an HTTP PUT, the Grants must be specified in the X-Grants HTTP
header, as the PUT specifies the file directly. Here’s an example showing how to upload a file that could
be downloaded by anyone, but only deleted by the user that creates it:
POST ${BASEPATH}/store/publicfile/stylesheet.css HTTP/1.1
Authorization: Bearer eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJuYW1lIjoiQkZPIFB1Ymxpc2hlciBVc2VyIiwiZ3JhbnRzIjpbImh0dHAiLCJ3cyIsImNvbnZlcnQiLCJnZXQiLCJwdXQiLCJkZWxldGUiXX0.xL0Pk5FPnGbWiiFG_3ICLYbnVpcn-ZZ_0jFUcoRQBYc
X-Grants: { "get": [ "*" ] }
Content-Type: text/css
…This is likely to be most useful when used with the extra_folders property for conversion: this way,
shared resources can be put in a folder and made public but read-only.
Overrides and Defaults
The overrides and defaults properties on an Authority can be used to override or provide default
values for any requests that it approves. This can be used to add a particular stylesheet to every
conversion request perhaps, or to ensure that generated files are available for public download without
the need to specify grants on every call to convert.
The syntax for both is a map containing other maps, one for each action they apply to (the only action
currently defined is convert. The keys are applied before (for defaults) or after (for overrides)
the properties specified in the call to convert.
Here’s an example showing how this could work. The goal here is to ensure that every call to convert
has a particular User CSS Stylesheet applied to the conversion (which is presumed to have been uploaded
earlier to a shared folder), and to set the default path to a keystore for any Digital Signatures.
In addition, the grants property is overridden so that the resulting
conversion is always available to download to users.
POST ${BASEPATH}/admin/configure HTTP/1.1
Content-Type: application/json
{
"authorities": [
{
"key": …
"grants": …
"defaults": {
"convert": {
"extra_folders": [ "brandingFolder" ],
"user_stylesheet": [ "branding-style.css" ]
"env": {
"bfo-ext-signature-keystore": "path/to/keystore.pkcs12",
"bfo-ext-signature-password": "secret"
}
}
},
"overrides": {
"grants": { "get": [ "*" ] }
}
}
]
}Where the property specified in overrides or defaults is an array property
(for example the user_stylesheet property in the above example), then overrides
and defaults behave slightly differently.
-
defaultswill be inserted before any values specified by the user - the arrays will be merged. -
overrideswill completely replace any values specified by the user.
Static website
Other than the Store mentioned at the top of this document,
the only other file-system access made by the BFO Publisher web-service
is to a directory which can be used to serve static pages, for a simple website.
This is optional - if set, it is checked after any of the URLs described in this document
(so it’s not possible to override /store, for example).
Again, as this involves access to the filesystem it requires the secure mode to be set.
The static_path option is simply the absolute path to the directory to serve web pages from. It may contain a 404.html page which is
served for any 404 responses. Symbolic links are followed, but only within that directory.
If set with the serve_help option, the path for the help files and live site test files is checked last, after the static_path.
WebSockets
The WebSocket interface is almost identical to the HTTP interface described above. WebSocket messages can be text or binary - for BFO Publisher, text messages must always be formatted in JSON and binary messages always populated in CBOR.
The WebSocket API is different to the HTTP API in the following ways.
-
HTTP headers are not typically used with WebSockets, so instead of setting the
Authorizationheader toBearer JWT-token(where JWT-token is the JWT token), the supplied JSON or CBOR should include anauthorizationproperty set to JWT-token in every message. The properties for both JSON and CBOR are read in order, soauthorizationshould be one of the first properties in the structure. As of release 1.4, theAuthorizationheader from the initial WebSocket connection will be used as a default if this is not set. -
WebSocket messages must have a
typeproperty set to the various actions listed above - example types areget,put,delete,convert,admin/configureand so on. A normal reply to any one of these messages will beget-response,put-response,admin/configure-responseand so on (although the client should be prepared for other response types too, egerror) -
As of release 1.4, CBOR requests sent to the server may be compressed using one of the algorithms listed in the
accept_encodingsproperty returned from a status request. Any compression will be detected and handled automatically and is on a per-message basis; it may be something to consider when sending large HTML files for conversion. Replies will never be compressed, as they are either small or contain a PDF (which is already compressed) -
WebSocket messages are standalone messages, so do not have the concept of request-then-response that is inherent to HTTP. To assist correlation, if the message sent by the client contains the property
message_idthen that property will be echoed back as thereply_toproperty in any response relating to that message. The value can be any string or number. -
The
get,putanddeletetypes use an identical syntax to the POST call to the/storeURL described in The Store section. Where an HTTP GET would return the file directly, WebSocket returns it as a structure which will look like the structure below.contentis always a buffer (for CBOR) or a Base64-encoded string (for JSON):{ "type": "get-response", "content_type": "application/pdf", "content": ... } -
WebSockets have one additional message type,
callback, which may be sent during a conversion if the conversion requires additional input from the user - usually because a username or password is required to access a resource. Thecallbackmessage is sent to the client - it must complete the fields for each entry in thecallbackarray (namefor a name callback,passwordfor password), change the type tocallback-responseand send the same object back in reply.{ "type": "callback", "reply_to": 123, "callback_id": 12313123, "callbacks": [ {"type": "name", "prompt": "http://example.com/secret" }, {"type": "password", "prompt": "http://example.com/secret" } ] } { "type": "callback-response", "reply_to": 123, "callback_id": 12313123, "callbacks": [ {"type": "name", "prompt": "http://example.com/secret", "name": "johndoe123" }, {"type": "password", "prompt": "http://example.com/secret", "password": "secret" } ] } -
When
convertis called withredirectset to false (the default), a message with typeconvert-responseis immediately sent in response with"complete":falseset on the structure. Logging messages follow, sent with"type":"log", then finally anotherconvert-responsemessage with"complete":trueset, containing thecontent_typeandcontentproperties set the type and value of the generated output, exactly as they would be retrieved with aget.
Here’s an example WebSocket conversion for such a convert operation,
showing the initial request and the multiple messages that follow:
{
"type": "convert",
"authorization": "...jwt token goes here...",
"message_id": 123,
"uri": "file.html",
"put": [
{"path": "file.html", "content_type": "text/html", "content": ... },
{"path": "style.css", "content_type": "text/css", "content": ... },
{"path": "logo.png", "content_type": "image/png", "content": ... }
]
}
{
"type":"convert-response",
"ok": true,
"reply_to": 123,
"complete": false,
"paths": { "folder": "7W4ABW2UySxh1ra4", "log": "7W4ABW2UySxh1ra4/log.txt" }
}
{
"type": "log",
"ok": true,
"reply_to": 123,
"log": { ... } /* will be many of these messages */
}
{
"type":"convert-response",
"ok": true,
"reply_to": 123,
"complete": true,
"content_type": "application/pdf",
"content": ...
}Java EE Servlet deployment
BFO Publisher ships with a bundled web-server based on Netty, chosen because it has extremely low overhead and is very fast. However some sites may prefer to integrate BFO Publisher into an existing Java EE Servlet container, such as Apache Tomcat or JBoss. This functionality was added in release 1.4
To deploy as a web-application requires a WAR file, which is simple a Zip file with the following structure
WEB-INF/
web.xml
configure.json
lib/
bfopublisher-bundle.jarweb.xml file is a boilerplate file which only requires the following content:
<web-app>
<listener>
<listener-class>
org.faceless.publisher.web.ServiceEngineServletContextListener
</listener-class>
</listener>
</web-app>configure.json file is an optional file which can be included to set the
initial configuration of the web-service - if present, it is sent to the server as
an admin/configure message immediately on startup. This can be used to configure
default user permissions and other rules.
| you should always set an initial configuration. See Security |
If preferred, bfopublisher.jar can be used instead of bfopublisher-bundle.jar,
so long as the required auxilliary Jars are included in the WEB-INF/lib folder.
Once the Jar is build, deployment is a usually just a matter of copying to the
web-apps folder of the servlet engine - if called publisher.jar, it will be
deployed to the /publisher path in the servlet engine. The deployment supports
the Web Socket and HTTP conversion API detailed in this section, but does not
include the static files (such as this help file or the API documentation).
If you’re wondering why we didn’t use a @WebListener annotation to make
deployment easier, the problem is that this annotation is in the
javax.servlet.annotation package which won’t be present in a non-servlet installation.
Many annotation-based libraries work by scanning all classes for their annotations,
and an annotation from an uninstalled package may result in a crash if the library
is not prepared for this.
|
WebService Reference
The Web Service can be accessed using standard HTTP GET, PUT and DELETE,
but these are all shortcuts for the universal interface used with HTTP POST
and WebSockets. The actions (specified with the path for HTTP or with the type key for WebSockets) are listed below with the
properties that can be included with each action.
The WebSockets section also lists some additional properties which can be included with each request. The responses are not described here, they are in general much simpler, just refer to the examples in the previous section.
convert (request)
Initiate a conversion.
The following parameters can be sent as part of a convert message.
Unless specified, all values are strings and are optional.
- url
-
the URL that will be converted. If unspecified it will be set to the path of the first item in the
putarray, and if noputarray exists it is an error. URL may be absolute or relative; relative URLs will be loaded from the current folder in the store - folder
-
the folder that the output files and log file will be created in. If unspecified, a new random folder will be created. Folder names are not hierarchical; permitted characters are ASCII letters, digits, underscore, hyphen and period.
- extra_folders
-
a list of folders to look in for resources after the current folder, highest priority first.
- output_name
-
the preferred name of the output file, for example
report.pdf. If unspecified an appropriate name will be chosen. - output_type
-
the media-type (also known as content-type) of the output. If unspecified defaults to
application/pdf. Other possible values areimage/svg+xml,image/tiff,image/pngor other Image types supported by Java. Theresolutionparameter can be used to control output resolution, egimage/tiff;resolution=150dpi, and SVG pagination and encapsulation properties may also be set using the corresponding media type parameters. (Note that only SVG pagination types that result in a single file are supported, thedirectorypagination type is not.) - redirect
-
if
true, the generated file will not be returned directly - instead a JSON object containing apathsproperty will be returned, with the path to the output file specified within it. Iffalse(the default) BFO Publisher will return the file as part of the same HTTP request when it is complete, or return an HTTP 500 if it fails. If the request was made over the WebSocket interface, a value offalsemeans BFO publisher will emit aconvert-responsemessage with"complete":truewhen the conversion is complete (see WebSockets section for detail) - baseurl
-
if set, any relative URLs within the input XML will be resolved against this value. It has the same effect as setting the
<base>element in the HTML, although at a lower priority. - lang
-
the BCP47 language code to use as the document default. This is identical to specifying
langorxml:langon the root element, but at a lower priority. - referrer_policy
-
the HTTP Referrer-Policy to use. This is identical to specifying
<meta name="referrer">in the source HTML, but at a lower priority. - user_stylesheets
-
an array of one or more stylesheets which will be treated as user stylesheets. Each entry is a URL and may be absolute or relative, with relative values resolved against the folders used for the conversion
- ua_stylesheets
-
an array of one or more stylesheets which will be treated as user-agent stylesheets. Each entry is a URL and may be absolute or relative, with relative values resolved against the folders used for the conversion
- processing_instructions
-
an array of one or more processing_instructions specified as a map with
typeanddatakeys - for example{"type":"xml-stylesheet", "data":"href=\"stylesheet.xsl\""}. These will be processed while the input file is being parsed, so relative values are relative to the document base (see XSLT). - proxy_servers
-
[Since 1.1] an array of zero or more strings containing the IP addresses of any HTTP Proxy Servers which proxy for the web-service. If incoming connections are made from one of these address, the value of any
X-Forwarded-ForHTTP header will used as the addess of the connection for logging and authorization. If multiple proxies add multipleX-Forwarded-Forheaders, each will be checked against this list in sequence. - env
-
a map containing environment properties which will be set as environment variables on the parse, accessible by the css
env()function. Special values of these are used to control the conversion process - for example:"env": { "bfo-sys-mathml-level": "core"}would restrict MathML 4 to the "core" set rather than the default extended set. See Appendix A: Environment variables - url_processors
-
an array of one or more URL Processors, which plug-in to the HTTP request engine to manage authentication, configure TLS, add client-certificates or trusted-roots, manage cookies and so on. Each type is described separately below
- timeout
-
the number of milliseconds to wait after the conversion begins before cancelling the job. The default value of 0 means jobs are never cancelled.
- put
-
an array of files to PUT to the current
folderbefore conversion begins. Each value is a map, the fields of which are described immediately below
- put[n].path
-
Required. the path to store this file against in the folder. Paths are typically relative but may also be absolute URLs. If the path is referenced from within the source document it will be retrieved from the folders used for the conversion if it exists there, otherwise it will be retrieved normally.
- put[n].content
-
Required. the content of the file to store in the folder. If the convert message is specified as a CBOR buffer (recommended) it will be stored verbatim. If it is specified as a JSON string or CBOR string, it will be Base64 decoded before storing. If Base64 decoding fails the UTF-8 value of the string will be used as input.
- put[n].content_type
-
the media-type (also known as content-type) of the resource. If not specified, it will be sniffed as the file is being uploaded.
- put[n].last_modified
-
the last-modified time of the file, in milliseconds since the UNIX epoch. Used if the file is to be attached to the PDF.
- put[n].expiry
-
the number of milliseconds after the file is last accessed that it should be considered for deletion, subject to the limitations of the store.
- put[n].grants
-
a map containing the access rights for this file. See Access Control below.
- put[n].trusted
-
boolean; if
trueand the user has theadmin/trustedgrant, mark the uploaded resource as trusted 1.3
URL Processors
There are several different types of URL Processor that can be added to the
configuration (they will be applied to all conversions) or to an individual
convert call.
The type property must be set and determines which other properties apply. The
different types and their properties are summarized here:
- type=ssl-default
-
This attaches the normal Java list of trusted certificates to any SSL request. This is the only URL Processor that is set by default, and this (or
ssl-mozilla) should always be set for normal use. - type=ssl-mozilla
-
This attaches the Mozilla CA Certificate List list of trusted certicates to any SSL request. This is the standard list of root certificates used by most browsers. It is a good alternative to the
ssl-default. - type=ssl-insecure
-
This allows all SSL certificates, and is a quick way to work with self-signed certificates. It does no checking on the certificate, so is not as secure as the other SSL options.
- type=password
-
adds support for standard HTTP Basic or Digest password security to a request. if a name and password are specified, they will be used without prompting. Otherwise, if using WebSockets then a
callbackmessage will be sent to retrieve the name and password from the user.- name
-
the username to use for the login.
- password
-
the password to use for the login.
- realm_match
-
an optional array of regular expressions which, if set, will be applied to the
realmsent by the server. At least one must match for the password to be applied. If this array is empty or the parameter missing, the password is always applied (subject to thematchproperty described below)
- type=aws4
-
adds support for the AWS4 authentication scheme used to access files stored on Amazon S3 and compatible systems. BFO Publisher will only download files from the store, so authentication is no different to regular password authentication. As with the
passwordtype, ifnameandpasswordare not included they will be requested via thecallbackmessage.- name
-
the access-key to use for the login.
- password
-
the secret-key to use for the login.
- type=ssl
-
adds either a custom trust store (to add trusted root certificates), a custom identity store (to add SSL Client certificats) or both.
- trust
-
the URL of a keystore containing one or more X.509 Cerfiicates which will be used as trusted root certificates.
- identity
-
the URL of a keystore containing one or more private keys and their corresponding X.509 Cerfiicates which will be used as SSL client certificates.
- password
-
if
identityis set, this is the password that is used to access theidentitykeystore.
- type=cookie-store
-
adds a store to read and write HTTP Cookies.
Each entry may also have an optional match parameter:
- match
-
an array of one or more regular expressions which will be matched to the URL. the URL Processor will only be applied if one matches (if no
matcharray exists, or it’s empty, the processor is always applied.
Here’s an example showing a url_processor array that adds a client-certificate,
on top of the regular list of certificates, and adds a username/password for a
specific site before falling back to prompting the user:
{
"url_processors": [
{
"type": "password",
"name": "myusername",
"password": "my-secret-password",
"match": [ "//example.com", "//login.example.com" ]
},
{
"type": "ssl",
"identity": "http://myserver.com/path/to/identity.pkcs12",
"password": "my-secret-keystore-password"
},
{
"type": "password"
},
{
"type": "ssl-default"
}
]
}We recommended always having an empty password processor and
either ssl-default or ssl-mozilla as the final two processors,
and this is the default setup.
get (request)
Retrieve a file from The Store. Normally only called from WebSockets, as a standard GET can be used with HTTP
- path
-
The path to retreive from the store. Required.
delete (request)
Delete a file from The Store. Normally only called from WebSockets, as a standard DELETE can be used with HTTP
- path
-
The path to delete from the store. Required.
put (request)
Put a file in The Store. Normally only called from WebSockets, as a standard PUT can be used with HTTP
Parameters are anything that can be set on
a single item in the put array
for a convert action.
admin/configure (request)
Configure the server for use - see Administration
- cache_size
-
Integer. The number of resources to be kept in a memory-sensitive LRU cache in case they’re requested again. Defaults to 200.
- max_threads
-
Integer. Sets the number of threads that will be available for conversion (each conversion process is largely single threaded). Defaults to 0, which means the number of cores available to Java.
- max_connections
-
Integer. The maximum number of network connections to accept to the web-server; further connections will result in an HTTP 503 error or will just be silently dropped. The default is 100, and a value of 0 means "no application limit" - there may be limits imposed by the underlying Netty server or the OS.
- max_queue_size
-
Integer. The number of Jobs to queue when
max-threadsconversions are already in progress. The default is 0, which means no limit. If this is set lower, conversion requests may be rejected. - max_buffer_size
-
Long. The maximum number of bytes that can be sent in a single request over HTTP or WebSocket. This value is used only if the corresponding key is not set in any Authority that authorizes the request.
- lang
-
the default value of the property with the same name that’s passed into
/convert - referrer_policy
-
the default value of the property with the same name that’s passed into
/convert - user_stylesheets
-
the default value of the property with the same name that’s passed into
/convert - ua_stylesheets
-
the default value of the property with the same name that’s passed into
/convert - processing_instructions
-
the default value of the property with the same name that’s passed into
/convert - env
-
the default value of the property with the same name that’s passed into
/convert - url_processors
-
the default value of the property with the same name that’s passed into
/convert. - simple_api
-
whether to allow the "simple" version of the HTTP API, which makes use of the
multipart/form-dataContent-Type and the HTTPPUTandDELETEmethods to interact with BFO Publisher, rather then encoding requests as JSON or CBOR. Web-browsers do not send theOriginHTTP header for simple API requests so they cannot be protected by CORS (see Access Control). For this reason, thesimple_apikey may be set to false to require that all API calls use JSON or CBOR 1.4. - license
-
the license code for BFO Publisher, supplied by BFO when the product is purchased to remove the trial-version stamps from the PDF.
- egress_filter
-
the policy to use for the egress filter used to limit access to external resources, this is a expression string describing the egress filter policy. See Egress Filtering for more detail. This is a secure option.
- store
-
a map which specified which Store to use, and configuration values for the Store. If it contains the key
classname, that is the Java classname of a subclass ofStore- if this differs from the current Store, it will be replaced. Other properties can control the Store operation - they will vary across Store types, but the following are defined for the defaultFileStoretype;- store.path
-
the directory on the filesystem to store files in. Defaults to
java.tmpdir - store.default_expiry
-
if no expiry is specified when uploading a resource, this value determines the default. It is the number of milliseconds after a File in the Store is last accessed befor the File is considered for deletion. Defaults to 604800000, which is 7 days.
- store.max_expiry
-
the maximum values that can be specified for
expiryfor any file uploads. Values larger than this will be capped. Default is 0, meaning no max.
- authorities
-
a list of signing authorities which will be used to grant access to BFO Publisher. See Access Control below for full details on these parameters
- authorities[n].key
-
the JWK key used to verify any Bearer tokens supplied in calls to this web service, or the word
noneto match all requests, including anonymous requests. - authorities[n].grants
-
a list of strings naming the grants which this Authority is allowed to approve. The wildcard
*means match any character except '/' and the wildcard**means match any character. Examples would bestatus,admin/statusorcustom/token/myactionfor individual grants, or**,*,admin/*orcustom/token/*for wildcard matches. - authorities[n].from
-
[Since 1.1] an optional list of strings listing the IP addresses to match against this Authority (if unspecified it defaults to
["*"]to match all IP addresses). Addresses are specified in the following formats:-
*will accept all addresses -
127.0.0.1will accept the specified IPv4 address -
192.168.0.0/16will accept the specified IPv4 address range -
::1will accept the specified IPv6 address -
2001:db8::/48will accept the specified IPv6 address range -
Each of these can have a
!in front of it to reverse the logic - if any address with a!prefix is matched, the authority does not match
-
- authorities[n].max_buffer_size
-
the maximum number of bytes that can be sent in a single request over HTTP or WebSocket for a request approved by this Authority.
- authorities[n].overrides
-
a map of properties which is applied over any properties specified by the user, overriding their supplied values
- authorities[n].defaults
-
a map of properties which is applied under any properties specified by the user, setting defaults which can be overridden by the user
- extensions
-
a list of maps that describe extensions to be added or removed from Publisher 1.3
- extensions[n].class
-
the class name of a
ReportFactoryExtensionclasss to be added or removed the list of extensions used by BFO Publisher. Extensions that are already in the list will be silently ignored; no duplicates are possible. If the class name cannot be resolved, it will be tested with theorg.faceless.publisher.extprefix added before failing. So for example,"extensions": [ { "class": "FreeMarkerExtension" } ]will add theFreeMarkerExtensionto Publisher. - extensions[n].remove
-
if this optional boolean is true, the extension will be removed rather than added
- extensions[n].configuration
-
if this optional value is set, it will be passed to the
configure()method of the extension.
Finally, when the web service is running as a standalone web server there are some additional configuration options that can be set, which do not apply when the web service is running as a web application in an existing servlet engine.
- server.name
-
The value of the
Serverheader in any response, ornullto use the default. An empty string disables the header entirely. - server.http_port
-
The port the server should listen to for HTTP requests, or 0 to disable HTTP entirely. The default value is 8080.
- server.https_port
-
The port the server should listen to for HTTPS requests, or 0 to disable HTTPS entirely. Note that HTTPS also requires a
server.keystoreto be set. The port must be a different value to theserver.http_port. The default value is 8443. - server.http_interfaces
-
The list of interfaces the server should listen on for HTTP requests; a string, a list of strings (eg
["lo1", "eth1"], or"*"to listen on all interfaces (the default) 1.4. - server.https_interfaces
-
The list of interfaces the server should listen on for HTTPS requests; a string, a list of strings (eg
["lo1", "eth1"], or"*"to listen on all interfaces (the default) 1.4. - server.serve_help
-
If this is true (the default), the help files - including this one - and the simple web interface for testing BFO Publisher are served from the embedded web server. If false they will return 404.
- server.prefix
-
The prefix that should be applied to all URL paths used by the web service. The default is
/which means that (for example) the store is accessible on/store, but setting this to/publisherwould move the store URL to/publisher/store. When running the web service behind a path-based proxy, it’s a good idea to set the prefix to match. - server.keystore
-
The keystore to use for the key information required to enable HTTPS. The keystore can be specified in a number of different ways:
-
as a URL to a PKCS#12, JKS or JCEKS format
java.security.KeyStore, or to a file containing one or more PEM encoded X.509 certificates and exactly one PEM encoded private key. -
the special URL
about:identitycan be used to create a self-signed identity on-the-fly. Fragment Parameters to the URL control the details of the identity, and include:-
CN - the common name to use, eg
about:identity#CN=myservername -
algorithm - the algorithm to use, eg
about:identity#algorithm=SHA256withECDSA -
curve - for elliptic-curve algorithms, the curve to use (defaults to secp256r1)
-
provider - the
java.security.Providerto use to create the identity -
days - the validity of the self-signed certificate (defaults to 365)
-
keylength - for RSA algorithms, the length of the key (defaults to 2048)
-
anything else - will be treated as an X.500 field of the identity being generated.
-
-
a JWK Key Set listing exactly one private key and one or more X.509 Certificates, with the server certificate first in the list.
-
- server.password
-
The password required to access the keystore set by
server.keystore, if required. - server.static_path
-
The optional directory from which to serve static files that don’t match any other URL recognised by the web service. This is a secure option - see Security for more detail.
- web_app.websocket_controller-class
-
String. The Java classname of the controller for the WebSocket interface. Override this with a subclass of
WebsocketControllerto add new functionality to the WebSocket interfae - web_app.http_controller_class
-
String. The Java classname of the controller for the HTTP interface. Override this with a subclass of
HttpControllerto add new functionality to the HTTP interface
Security
BFO Publisher inherently deals with URLs, retrieving them and converting them to PDF. This process has security implications which are described in this section, broadly broken down into risk categories.
|
When running the web-service, there are two key concepts that don’t apply to API use. Covered first in its own section is Access Control: because there is no point in checking the locks if you have given the keys to everyone. The second thing to know is that adjusting some of the below settings requires secure mode to be enabled. Running in secure mode means the administrator has secured the web-service appropriately. It is not enabled by default. To enable secure mode:
When not in secure mode, the web service will limit changes to some settings that would reduce security. |
Egress Filtering
Egress filtering prevents the exfiltration of data from the local filesystem or network by hiding it in a PDF.
A simple example would be converting a file with the line <link rel="attachment" href="file:/etc/passwd"/> to PDF;
without any egress filtering, the password file would be attached.
To understand how to prevent this we need to introduce two concepts.
-
a resource is anything that BFO publisher needs to load to do its job: an HTML file, an image, a stylesheet etc.
-
an origin is where that resource was loaded from. HTML defines origin in more detail.
Whenever a request is made for any resource, the egress filter determines whether its URL can be accessed, whether the URL should be modified, or whether the access should be denied. This decision is based solely on the URL of the resource and the URL of the origin.
An instance of the EgressFilter interface is typically specified using a simple
grammar. The following individual filters are predefined:
- relative
-
accepts the URL if it has the same scheme and host as the From-URL
- trustworthy
-
accepts the URL if it is has a scheme of
data,about, or some others used internally by BFO Publisher (the term comes from the W3C) - file
-
accepts the URL if it is has any scheme that would result in local filesystem access:
file,jaror similar - network
-
accepts the URL if it is has any scheme that would result in network access:
http,https,ftpor similar - lan
-
a subset of
networkthat matches only non-routable addresses such ashttp://127.0.0.1,http://192.168.0.1,http://server.local,http://server,\http://[::1],\http://[fd02::1]orhttp://169.254.0.1 - internet
-
a subset of
networkthat matches only routable addresses - the opposite oflan - from-file
-
identical to
filebut tests the origin URL - from-network
-
identical to
networkbut tests the origin URL - from-lan
-
identical to
lanbut tests the origin URL - from-internet
-
identical to
internetbut tests the origin URL - from-api
-
for API use, matches files added via the API (eg stylesheets); for the web-service, matches any files uploaded to the store for conversion
- path(arg, …)
-
if the URL uses the
filescheme, it’s path must begin with one of the comma-separated list of string arguments. Non-file URLs are always accepted. - type(arg, …)
-
if the URL uses the
filescheme, it’s media-type must match one of the comma-separated list of string arguments. Non-file URLs are always accepted. - scheme(arg, …)
-
the URL scheme must match on of the comma-separated list of string arguments.
- from-scheme(arg, …)
-
identical to
scheme()but tests the origin URL - match(search)
-
the URL must match the search argument, which is a string containing a Java-syntax regular expression
- replace(search, replace)
-
similar to
match(), but the URL is modified by replacing every subsequence that matches the regular expression search with the given string replace. - default
-
shorthand for
trustworthy or from-file or not file, which is the default policy for non-webservice use - fail
-
the URL is rejected.
Individual filters may be combined using the terms not, and, or, then (for the implies logical condition)
and parentheses are used to group filters. Some examples:
When using the API, the
ReportFactory.setEgressFilter
and
Report.setEgressFilter are used to
control egress filtering.
When using the web service the egress_filter configuration property must be
set in the admin/configure (request) action.
In order to do this the service must be run in secure mode.
This will allow the egress_filter to be changed remotely by anyone granted admin/configure rights,
which includes anonymous users by default. This change could allow read-access to the filesystem and local-network
of the computer that BFO Publisher is running on.
XXE, XInclude and XSLT
XML has a number of method for including content from external files, two of which have become notorious for causing security problems:
XML External Entities (XXE)
XML External Entities are a method of loading external content into an XML file. A good summary of many of the attack modes they enable is at https://github.com/Mehdi0x90/Web_Hacking/blob/main/XXE.md.
The most obvious external entity for many XML files is the DTD, it’s not uncommon for those DTDs to be
modularised by including other DTDs, and without a DTD entities like &nsbp; will fail to parse.
BFO Publisher ships with a large list of DTDs commonly used for parsing XHTML, SVG and MathML, which are
part of the Jar and can always be loaded. Other external entities (including DTDs) are denied by default
unless the bfo-sys-xml-external-entities environment property is set on the ReportFactory object:
ReportFactory factory = new ReportFactory();
factory.getEnvironment().put("bfo-sys-xml-external-entities", true);XML External Entities may also used by XSL stylesheets, and access to these is controlled by the same flag; when disabled, the stylesheet will load but any external object is references will be blocked.
XXE bugs are often thought of as particularly dangerous, due to them being a) poorly understood and b) enabled by default when parsing XML in Java - a bad combination! However enabling it as shown here isn’t particularly risky. External entities are subject to egress filtering just like any other external resource, so a DTD loaded from an HTTP URL will not be allowed to access the file system.
XML Include
XInclude is a more direct method of including content into XML, although as it’s not enabled by default
in Java XML parsers it’s less well known than XXE. It’s useful and is fully supported by BFO Publisher, but
is also disabled by default unless the content to be included is in memory (for example, it comes from a
data: URL, or has been uploaded over the web-service).
To enable xi:include processing, the bfo-sys-xml-include environment property must be set on the ReportFactory object
ReportFactory factory = new ReportFactory();
factory.getEnvironment().put("bfo-sys-xml-include", true);If using the web-service, both of these properties can be
set in the admin/configure (request) action.
Denial of Service
Denial Of Service attacks are theoretically applicable to BFO Publisher. When it is requesting content from a
URL (eg an image, font or stylesheet from a HTTP URL), the requests will eventually timeout if the server doesn’t respond.
The bfo-sys-resource-timeout environment property controls how long it should wait, which defaults to 10s and can be
set per-document like other Environment variables.
The BFO Publisher Web Service is built on Netty, which is very efficient at handling multiple connections.
There are several ways to limit the load on the server, listed here in rough order of first to last resort.
All these can be configured by a call to
admin/configure (request):
-
the
max_threadsproperty limits the number of simultaneous conversions -
the
max_queue_sizeproperty limits the number of queued conversions -
the
max_buffer_sizeproperty limits the number of bytes that can be sent in a single network request -
the
max_connectionsproperty limits the number of simultaneous network connections
Secrets and Authentication
There are some situations where sensitive information is required that may not be appropriate to embed in the document being converted - for example, when creating a PDF that contains a digital signature, the password for the signing key may need to be kept secret.
There are two ways to deal with this.
-
the information can be specified in advance using Environment variables
-
the information can be requested on demand by way of a Callback.
Environment variables have already been discussed. Take this example, which
refers to a keystore but doesn’t specify the password to access it
<html>
<body>
This document contains a digital signature
<object type="bfo/signature">
<param name="keystore" value="path/to/keystore.pkcs12">
<param name="alias" value="myidentity">
<img src="https://test.com/secret/signature.svg">
</object>
</body>
</html>The environment variable bfo-ext-signature-password will be checked for the missing
password, as described in Signature defaults.
Another situation where secret information may be requires is to access a resource
that requires a password - in this example, lets presume the SVG requires an HTTP
username and password to access it. This can’t be specified with an environment
variable; it has to be done using a
PasswordAuthenticationURLConnectionProcessor
(see Customizing: URL Processors). Other similar classes exist for other types of
authentication, such as
OAuth2
and
AWS4.
Note that all of these URL Connection Processor classes will defer to an appropriate
Callback if they can’t supply the required information.
- NOTE
-
Environment variables containing the string
password,pinorsecurein their names or beginning withbfo-ext-signaturecannot be referenced with theenv()function, preventing their values from being embedded into the parsed content of the document; say withdiv::before { content: env(bfo-ext-signature-password) }(see Signature defaults). They are also not reported in the status (request) response from the web-service.
Callbacks
When information is not supplied in advance, it needs to be requested on demand by asking the user.
Both the
Report
and
ReportFactory
have a setCallbackHandler method designed to support this. Taking a standard Java
CallbackHandler,
if specified this will be called to retrieve the required information on demand.
This will be called whenever a password or other secret information is required
to access a resource. Callbacks are typically the standard
PasswordCallback
and
NameCallback,
but we’ve also added our own
OAuth2Callback
to this list which is used when requesting content protected by OAuth2.
To show a simple example, the command-line client we ship includes a CallbackHandler to prompt for
information at the command line.
import javax.security.auth.callback.*;
import java.io.Console;
ReportFactory factory = new ReportFactory();
factory.setCallbackHandler(new CallbackHandler) {
public void handle(Callback[] callbacks) {
Console console = System.console();
for (Callback cb : callbacks) {
if (cb instanceof NameCallback) {
NameCallback ncb = (NameCallback)cb;
System.out.print(ncb.getPrompt() + ": ");
ncb.setName(console.readLine());
} else if (cb instanceof PasswordCallback) {
PasswordCallback pcb = (PasswordCallback)cb;
System.out.print(pcb.getPrompt() + ": ");
pcb.setPassword(console.readPassword());
}
}
}
});Converting the HTML shown above will result in a prompt on the command line to "Enter password".
If no CallbackHandler were specified or if the user didn’t enter a password, signing will fail.
Although names and passwords are the most obvious case, some callbacks may just require a name,
and it’s possible to combine Environment variables and Callbacks as required.
For example, the GlobalSign QSS signing service requires several keys: keystore, apikey
and apisecret are all used to specify information required to use the service, and that may
be site-wide - they apply to the organization as a whole. The identity key is also required
to identify the individual signer.
If we presume the following environment variables have been set:
-
bfo-ext-signature-enginetoglobalsign.qss -
bfo-ext-signature-keystoretopath/to/keystore.pkcs12#password=secret -
bfo-ext-signature-apikeyto…(a value supplied by GlobalSign) -
bfo-ext-signature-apisecretto…(again, supplied by GlobalSign)
then the only required parameter is identity.
With an appropriate CallbackHandler set, this will be the only information
the signer is prompted for:
<html>
<body>
This document contains a digital signature
<object type="bfo/signature">The Signature</object>
</body>
</html>Note that the Web Service is configured with a CallbackHandler that forwards to the client,
provided the client is connected over a web-socket. See WebSockets for more information.
Authenticated resources
Access to remote resources that require authentication, such as logging on to a remote server, is enabled in one of two ways:
-
for simple HTTP authentication, by specifying the username and password as part of the URL, eg
http://user:password@example.com/file -
by configuring URL Processors, to supply HTTP authentication, SSL client certificates or AWS4 authentication.
URL processors are transparent to the application, and cannot be queried by a document being processed
so any parameters such as keystore information or passwords is safe. If a password is specified
directly in a URL, eg http://user:password@example.com/file, the username and
password are excluded from any diagnostic and log records.
Metadata
By default the metadata included in the PDF will include details of the conversion, including the time and the URL of the file
that was converted - which has the potential to leak private information (and why we’re covering it in the "Security" section).
By default the URL is only included if the path is a public URL (defined the same way as the "internet" source
when Egress Filtering), but this can be altered by setting the bfo-metadata-location environment property to
-
none- never include the URL of the file that was converted -
always- always include the URL of the file that was converted -
public- include the URL of the file that was converted if it is a public URL (the default, see above) -
if set to any other value, that value will be used as the location.
CORS
Cross-Origin Resource Sharing is the primary security model on the web, where its purpose is to prevent leakage of information between domains within a web-page; for example, preventing a web-page containing third-party JavaScript from being to exfiltrate information.
BFO Publisher does not support JavaScript, so CORS is largely irrelevant. BFO Publisher still respects
CORS attributes and headers, but their use is simply to control which HTTP headers are sent with requests;
specifically the Cookie and Referer headers.
Appendix A: Environment variables
Below is a largely complete list of environment variables recognised by the current release. Others may be added and the functionality of some may be removed; this list is for information purposes only.
| Name | Default | Description |
|---|---|---|
User Properties |
||
bfo-lang |
"" (empty string) |
the default language when no other value is known (also the environment language for SVG) |
bfo-lookahead |
true |
should the parser run in lookahead mode (see Lookahead mode) |
bfo-stylesheet-alternate |
none |
the alternate stylesheet name to use |
bfo-pages |
auto |
Guess for the number of pages in the document (to better-size the |
bfo-publisher-version |
the current version of BFO Publisher (read-only) |
|
bfo-format |
the output format - "pdf" or "svg" (read-only) |
|
bfo-location |
the URI of the document being parsed (read-only) |
|
bfo-metadata-location |
public |
the URL to record in the Metadata as the source for the generated PDF: |
bfo-table-row-group-buffer |
100 |
the number of table rows to buffer when searching for a table-footer-group element: |
bfo-metadata-rdfa |
root |
which nodes to generate RDFa metadata for: |
bfo-metadata-microdata |
root |
which nodes to generate Microdata metadata for: |
bfo-metadata-indent |
0 |
when formatting XMP metadata, the number of spaces to indent each nesting level by, or 0 for no indent. 1.4 |
System Properties |
||
bfo-sys-html-xml-base |
false |
does HTML input accept |
bfo-sys-mathml-level |
extended |
level of MathML support: |
bfo-sys-resource-timeout |
30s |
how long to wait before resource requests time out |
bfo-sys-same-origin-policy |
true |
enforce CORS same-origin policy for any network requests |
bfo-sys-hold-queue-length |
40 |
how many elements to buffer before starting layout |
bfo-sys-display-run-in |
new |
the |
bfo-sys-display-columns |
true |
whether the layout engine recognises the |
bfo-sys-display-grid |
true |
whether the layout engine recognises the |
bfo-sys-display-flex |
true |
whether the layout engine recognises the |
bfo-sys-content-in-nodes |
false |
determines whether the full range of values for the |
bfo-sys-content-in-content |
false |
determines whether the the |
bfo-sys-viewport-zoom |
1 |
the default value for |
bfo-sys-fallback-id-attribute |
"id" "xml:id" |
the attributes to use for the |
bfo-sys-fallback-class-attribute |
"class" |
the attributes to use for the |
bfo-sys-fallback-base-attribute |
"xml:base" |
the attributes to use for the base-url on elements in unrecognised namespaces |
bfo-sys-fallback-lang-attribute |
"xml:lang" |
the attributes to use for the language on elements in unrecognised namespaces |
bfo-sys-fallback-style-attribute |
none |
the equivalent to the HTML |
bfo-sys-first-letter-skips-inline-marker |
true |
are inline markers from list-items considered part of the first letter? https://github.com/w3c/csswg-drafts/issues/4506 |
bfo-sys-zero-leading-expands-linegap |
false |
do fonts with a line-height of 1em have padding added to the linegap (as Firefox does) or to the ascent/descent (as Chrome/Safari do) |
bfo-sys-initial-letter-align |
false |
can the initial-letter use baseline-shift/alignment-baseline? |
bfo-sys-intrinsic-stretch-padding |
false |
does replaced content sized to stretch fit include padding (as Chrome/Safari) or not (as Firefox) |
bfo-sys-counter-image-suffix |
" " (two spaces) |
the suffix to automatically apply after an image in a counter. |
bfo-sys-font-step |
1.2 |
step adjustment for |
bfo-sys-font-smallcaps-size |
0.7 |
the size to multiply font-size by when synthesizing small-caps |
bfo-sys-page-first-of-group |
false |
whether the |
bfo-sys-target-text-max-length |
80 |
how manyu characters of text to store from each node with an id to support the |
bfo-sys-legacy-css-common |
false |
whether to automatically support a set of legacy prefixed CSS properties |
bfo-sys-legacy-css-ah |
false |
whether to automatically support a subset of CSS properties used by Antenna House™ Formatter |
bfo-sys-legacy-css-epub |
false |
whether to automatically support a subset of CSS properties used by ePub documents |
bfo-sys-legacy-css-all |
false |
whether to automatically support all above legacy subsets CSS properties |
bfo-sys-string-counter-by-reference |
false |
does string-set(x, counter(page)) copy the counter by reference? https://github.com/w3c/csswg-drafts/issues/4740 |
bfo-sys-svg-respect-tainting |
true |
whether we honour the tainting rules for SVG filters (they have no security implications in BFO Publisher) |
bfo-sys-svg-non-uniform-turbulence |
false |
does the SVG feTurbulence algorithm use the legacy, non-uniform vector |
bfo-sys-backdrop-filter-color |
white |
color over which the root element should be composed for CSS |
bfo-sys-svg-blur-default-edgemode |
none |
default edgeMode for SVG blur filter: spec has none, all implementations use duplicate |
bfo-sys-svg-edgemode-box |
filter |
which box to treat as the edge for the "blur" filter - |
bfo-sys-svg-path-earlyclose |
false |
whether we support the SVG path "early close" mechanism from SVGnext? |
bfo-sys-svg-path-bearings |
true |
whether we support the SVG path bearing command from SVGnext? |
bfo-sys-break-all-allows-break-edge |
true |
whether a break opportunity exists before the first char in a |
bfo-sys-viewport-units |
base |
how to resolve vw/vh units? |
bfo-sys-reorient-svg-images |
false |
when embedding images in an SVG, should we rotate any images that rely on the EXIF tags for rotation, which is unsupported by many SVG renderers |
bfo-sys-colors |
none |
which extra color functions we recognise - list of strings including "cmyk" "rgb-icc" "gray" "device-gray" "-ro-spot" "prince-color" |
bfo-sys-page-size-nnn |
default pages sizes; for example, the user-agent stylesheet includes a rule |
|
bfo-sys-font-xheight-derive |
false |
whether we derive the x-height form a font from the lowercase 'o', as specified. Can lead to odd results |
bfo-sys-font-capheight-derive |
false |
whether we derive the cap-height form a font from the uppercase 'O', as specified. Can lead to odd results |
bfo-sys-font-xheight-default |
0.8 |
the default x-height (if no other way is available to determine it) |
bfo-sys-font-capheight-default |
1 |
the default cap-height (if no other way is available to determine it) |
bfo-sys-font-superpos-default |
0.34 |
the default superscript baseline shift |
bfo-sys-font-superpos-default |
-0.2 |
the default subscript baseline shift |
bfo-sys-font-family-default |
serif |
the default font-family |
bfo-sys-raster-pixels-max |
4194304 |
the maximum number of pixels when rasterizing images; anything images above this will be downsampled 1.4. |
bfo-sys-raster-resolution-default |
serif |
the default resolution to use when rasterizing images |
bfo-sys-raster-resolution-max |
infinity |
the maximum resolution for any raster image stored in the PDF; anything above this will be downsampled |
bfo-sys-raster-resolution-target |
infinity |
for any images downsampled due to the above setting, the resolution to downsample them to (used resolutionwill be the min(bfo-sys-raster-resolution-max, bfo-sys-raster-resolution-target) |
bfo-sys-running-combines |
true |
whether |
bfo-sys-page-collapse-margin |
never |
whether the margin on :root collapses with the page-margins ( |
bfo-sys-text-indent-percentage-old |
false |
whether to resolve percentages in |
bfo-sys-svg-features |
see text |
the list of supported SVG 1.1 features (the default is the full list of "SVG-Static" from SVG 1.1, excluding "Font" but adding "Hyperlinking" and a few others. Used by the |
bfo-sys-svg-extension-nnn |
add a url to the list of SVG 2.0 extensions. For example, the user-agent stylesheet includes a rule |
|
bfo-sys-epub-extension-nnn |
add a url to the list of EPUB extensions. |
|
bfo-sys-box-shadow-model |
default |
which model to use for calculation the spread for |
bfo-sys-xml-external-entities |
false |
whether XML external entity processing is enabled. Defaults to false (see Security) 1.4. |
bfo-sys-xml-include |
false |
whether XML xi:include processing is enabled. Defaults to false (see Security) 1.4. |
Media Properties |
||
bfo-media |
the media type: |
|
bfo-media-size |
A4 |
the media size - a shortcut for |
bfo-media-color |
24 |
the media |
bfo-media-resolution |
infinite |
the media |
bfo-media-overflow |
paged |
the media |
bfo-media-update |
none |
the media |
bfo-media-hover |
none |
the media |
bfo-media-scripting |
false |
the media |
bfo-media-monochrome |
0 |
the media |
bfo-media-color-scheme |
none |
the preferred color-scheme (default is no-preference which is effectively light, but a strong-preference for |
PDF Output Properties |
||
bfo-pdf-profile |
none |
list of PDF output-profiles to apply |
bfo-pdf-profile-feature-nnn |
initial |
turn on/off a specified PDF output-profile feature. Values are require, deny, ignore or initial |
bfo-pdf-page-grid |
none |
set this value to a length to draw a grid on the page, to verify position of content |
bfo-pdf-page-layout |
none |
set the initial layout of the document pages (values are SinglePage, OneColumn, TwoColumnLeft, TwoColumnRight) |
bfo-pdf-page-mode |
none |
set the initial UI pane to display when the doucment opens. Values are UseNone, UseOutlines for bookmarks, UseThumbs for thumbnails, UseAttachments for file attachments, or UseOC for optional-content layers |
bfo-pdf-rtl |
none |
set the "reading direction is RTL" option n the PDF metadata (values are true or false) |
bfo-pdf-view-displaydoctitle |
none |
set the "display document title in titlebar" option in the PDF metadata (values are true or false) |
bfo-pdf-attachment-presentation |
none |
for portfolio PDFs, request the specified presentation (values are detail, tile, hidden, filmstrip, freeform, linear or tree) |
bfo-pdf-attachment-target |
none |
when attaching dynamically created PDFs to form a document tree, set this value to root to propagate all attachments to the root document |
bfo-pdf-declaration |
none |
specify the URL of a PDF declaration to declare in the generated file (multiple values are allowed when specified with |
bfo-pdf-encrypt-print |
yes |
for encryption, the print permissions (values are no, lowres or yes) |
bfo-pdf-encrypt-change |
yes |
for encryption, the change permissions (values are no, forms, layout, annotations or yss) |
bfo-pdf-encrypt-extract |
yes |
for encryption, the change permissions (values are no or yes) |
bfo-pdf-encrypt-metadata |
yes |
for encryption, whether to encrypt the document metadata (values are no or yes) |
bfo-pdf-encrypt-cipher |
aes-256 |
for encryption, the encryption cipher (values are rc4-40, rc4-128, aes-128, aes-256 or aes-256-gcm) |
bfo-pdf-encrypt-password |
none |
for password encryption, the password required to open the PDF |
bfo-pdf-encrypt-admin-password |
none |
for password encryption, the password required to change the PDF permissions |
bfo-pdf-encrypt-recipient |
none |
for public-key encryption, the URL of a public key to add as a recipient (multiple values are allowed when specified with |
PDF Output Properties, additional (in the PDF specification, but with very limited support from PDF viewers) |
||
bfo-pdf-view-fullscreen |
none |
set the "open in fullscreen" option in the PDF metadata (values are true or false) |
bfo-pdf-view-hidetoolbar |
none |
set the "hide toolbar" option in the PDF metadata (values are true or false) |
bfo-pdf-view-hidemenubar |
none |
set the "hide menubar" option in the PDF metadata (values are true or false) |
bfo-pdf-view-hidewindowui |
none |
set the "hide window UI" option in the PDF metadata (values are true or false) |
bfo-pdf-view-fitwindow |
none |
set the "resize document to fit size of first page" option in the PDF metadata (values are true or false) |
bfo-pdf-view-centerwindow |
none |
set the "center window in middle of screen when opened" option in the PDF metadata (values are true or false) |
bfo-pdf-view-area |
none |
specified which page box to present as the boundaries when displaying the PDF on screen (values are CropBox, MediaBox, ArtBox, BleedBox and TrimBox) |
bfo-pdf-view-clip |
none |
specified which page box to clip the contents to when displaying the PDF on screen (values are CropBox, MediaBox, ArtBox, BleedBox and TrimBox) |
bfo-pdf-print-area |
none |
specified which page box to present as the boundaries when printing the PDF (values are CropBox, MediaBox, ArtBox, BleedBox and TrimBox) |
bfo-pdf-print-clip |
none |
specified which page box to clip the contents to when printing the PDF (values are CropBox, MediaBox, ArtBox, BleedBox and TrimBox) |
bfo-pdf-print-scaling |
none |
request how the page is scaled when printing. Values are None for no scaling, or AppDefault to use the default. |
bfo-pdf-print-duplex |
none |
request how the page is duplexed to media when printing. Values are Simplex for single-sided, DuplexFlipLongEdge or DuplexFlipShortEdge for double-sided |
bfo-pdf-print-matchtraysize |
none |
request the page is assigned to media based on tray size when printing (values are true or false) |
bfo-pdf-print-numcopies |
none |
request the printing defaults to the specified number of copies when printing (values are a number) |
Extension Properties |
||
bfo-ext-html-namespace |
none |
how to handle namespace extensions in HTML (see HTML Namespace Extensions) |
bfo-ext-signature-nnn |
default value for param nnn for any signature objects |
|
bfo-ext-index-division |
"//" |
the string to use for |
bfo-ext-index-subdivision |
"/" |
the string to use for |
bfo-ext-index-xref |
"->" |
the string to use for |
bfo-ext-index-sort |
"{ }" |
the string (or two strings separated by space) to use for |
bfo-ext-index-comma |
"," |
the string to use for |
bfo-ext-index-dash |
"–" |
the string to use for |
bfo-ext-index-separator |
"," |
the string to use for |
bfo-ext-mail |
default |
the Configuration the MailExtension should convert RFC822 messages. Current values are |
bfo-ext-spider |
none |
how the Spider extension attaches any content it traverses? |
Appendix B: Properties
This section lists every property recognised by BFO Publisher, along with link to the spec (or specs) that define them. If the property value varies from the official specification that’s noted, otherwise the property definitions can be retrieved from the listed specification.
bookmark-level
display
float
hyphenate-limit-chars
hyphens
initial-letter-align
letter-spacing
path-length
-bfo-pdf-tag
position
-bfo-raster-resolution
text-align
-bfo-text-decoration-skip-ink-clearance
white-space
word-spacing
Appendix C: Supported types
At Rules
File Formats for Replaced Content
-
image/tiff
-
image/png
-
image/jpeg
-
image/gif
-
image/x-portable-anymap
-
image/x-portable-bitmap
-
image/x-portable-pixmap
-
image/x-portable-graymap
-
image/jp2
-
image/bmp
-
image/svg+xml
-
image/* (with ImageIO plugin)
-
application/pdf
-
video/mp4
-
video/quicktime
-
model/u3d
-
model/prc
-
audio/mpeg
-
audio/x-wav
-
audio/x-aiff
-
audio/basic
-
audio/* (with AudioFileReader plugin)
The application/pdf replaced content supports the page and viewrect fragments as defined in RFC8118.
All image/* replaced content supports the generic xywh media fragment from https://www.w3.org/TR/media-frags/ to
embed part of an image. image/tiff also supports the page media fragment, to load a particular page - the first page is 1.
<img src="file.png#&xywh=200,200,100,50">
<img src="file.tif#page=1&xywh=200,200,100,50">
<img src="file.pdf#&page=2&viewrect=xywh=200,200,100,50">URL Schemes
-
file ("host" is unsupported)
-
jar (works for any Zip file)
-
imap (with
MailServerExtensionclass) -
classpath
The classpath URL scheme can be used to load an object from the classpath.
It takes a relative path from the Report class (classpath:data/nss.crt),
an absolute path beginning with a slash (classpath:/com/example/Name)
or an absolute path with dots (classpath:com.example.Name)
Appendix D: Report Generator
The Big Faceless Report Generator is BFOs first attempt at an XML+CSS to PDF converter, first releasted in 2001. It shares no code with BFO Publisher other than the underlying PDF library. However as it’s quite possible some users will wish to migrate from the Report Generator to Publisher, and this section will go into detail on how to do so.
The Report Generator uses a custom XML format that is similar to, but not quite the same as HTML. It also nominally uses CSS, although in practice the meaning of the properties and the parsing rules means that there are significant differences.
By contrast, BFO Publisher uses HTML and CSS, exactly as they are in the published specification. So migrating from Report Generator to Publisher means converting from the custom Report Generator XML and CSS to standard HTML and CSS.
BFO Publisher can do this in one pass, reading the Report Generator XML, converting to HTML, then parsing that HTML. To identify the Report Generator XML we need to assign it a Media-Type.
-
application/x-vnd.bfo.report;version=1for thereport-1.1syntax -
application/x-vnd.bfo.report;version=0for thereport-1.0syntax
Both of these will be automatically identified from the input files so there will rarely be a need to specify it explicitly. Which means parsing a Report Generator file with BFO Publisher is now fairly simple. Using the command line approach described in the Quick Start section:
$ java -jar bfopublisher-bundle.jar --format pdf --output out.pdf reportgeneratorinput.xmlThis should give you a PDF that is almost, but not exactly, the same as you would see from the Report Generator.
Almost? There are some differences:
-
inline vertical alignment as used in Report Generator is very different to how it’s supposed to be in CSS. This will be most noticable when mixing text or images with very different sizes on the same line. This is likely to need some manual adjustment.
-
the table layout algorithm, which determines the widths of each column based on its content, is different, although in many cases the differences are slight.
-
the
requoteattribute (which converts straight quotes into curly quotes) is not yet supported. -
the algorithm for determining whether a box can fit on the page is slightly different, with Publisher more likely to find it possible. Long documents may use slightly fewers pages in Publisher as a result.
-
Publisher has no support for the
axesgraphorpiegraphelements of the Report Generator -
Report Generator had no concept of collapsed borders in Tables. Emulating this exactly in Publisher is quite complicated and on some occasions we get this wrong.
-
The
overflowproperty in Report Generator worked in a very different way to CSS and cannot be duplicated exactly. -
superscript and subscript are positioned based on the correct font metrics, which puts them in a slightly differnet location.
-
list bullets are done very differently in Report Generator. BFO Publisher will attempt to duplicate the approach used in Report Generator, but is unable to do so for hierarcical lists. However CSS has a much better model for these, so it will always be simply to revert to the CSS list model.
-
Form element styling is slightly different.
There are also some layout bugs relating to display: flow-root which are particularly
obvious with this conversion, although these will be fixed over time.
Converting Report Generator input to HTML input
What we’ve shown above is the process for conversion Report Generator XML into PDF. But a proper migration from Report Generator to Publisher would need to focus on converting Report Generator XML into XHTML. Presumably the reason for migration is to access new CSS features, or to avoid the various issues with page-breaking that were an aspect of the Report Generator? If so, the fixes belong in the HTML and CSS, not the original input file.
BFO Publisher can write the HTML it generates from the Report Generator XML as an output format. Modifying the example above:
$ java -jar bfopublisher-bundle.jar --format application/x-vnd.bfo.publisher+xml \
--output out.xhtml reportgeneratorinput.xmlThe Media-Type application/x-vnd.bfo.publisher+xml will generate XML output based on the
input. It can be used with any input type, although if you’re reading in a supported XML
format like XHTML it will simply be an identity transform.
However when the input has special processing it can be useful. In particular, when:
This approach will show you exactly what is being parsed by BFO Publisher. And, because the output is now regular HTML, you can load it into a web-browser to see how it works.
Most of our Report Generator customers are using some sort of template, populating it with data from a source, then feeding that XML input through the Report Generator to create a PDF. The approach for migration we would recommend is:
-
Generate a sample XML input and save it to a file.
-
Run it through BFO Publisher as shown in the example above, to convert Report Generator XML into generic HTML.
-
Open that HTML in a browser.
-
Start editing the HTML. In particular
-
the generated HTML will have CSS rules that don’t apply and can be dropped.
-
the CSS will attempt to be bug-for-bug compatible with the Report Generator - for example, Report Generator could not break table-cells across pages, so the CSS contains a rule
th, td, li { break-inside: avoid }. Removing this will allow cells and list items to break at page ends. -
the CSS will all be in the one file, included as a
<style>. Thebfo-titleattribute on each<style>element shows the source of the data, and it will include (for example) our system stylesheetsreport-1.1.cssandconversion.css. It may make sense to break those out into external stylesheet files and include them with<link> -
in many cases the CSS we generate is quite awful, to try and retain compaibility with Report Generator. For example, lists bullets are created using absolutely positioned generator content. Removing all the CSS that does this and simply relying on regular CSS list bullets is certainly the better option.
-
-
Once the HTML is styled to your satisfaction, reverse the process in step 1 - create a template from the HTML and use that HTML template instead of the original Report Generator template.
-
At that point the Report Generator can be removed from the code and BFO Publisher substituted in.
Finally, we should note there is no particular need to do this. The BFO Publisher codebase is ten times the size of the Report Generator; it is a much more capable product, but simple means fast. The Report Generator uses no caching - fonts, images, stylesheets etc are parsed each time they’re used, but the layout is very quick. By contrast, BFO Publisher will cache and share resources like these, but layout is slower. And of course, there will be a development cost to any migration, although for customers with support coverage BFO will certainly be able to help with this.
Out advice would be: if the layout limitations of the Report Generator are causing problems then consider migration, otherwise stay where you are.
Appendix E: Licensing
BFO Publisher run run unlicensed, but will apply a stamp to each page it generates.
On purchasing a license BFO will supply a license JAR, normally called
bfopublisher-license.jar. Add this file to the Java CLASSPATH to remove the Trial
Version stamp. If running the bfopublisher-bundle.jar as a JAR, it’s enough to
place the license JAR in the same folder.
Alternatively double click on the Jar to see the license key as a String:
this can be passed into the /admin/configure method of the web-service, or
passed to the
ReportFactory.setLicenseKey()
method in the API.
License Agreement
The license agreement for this version of BFO Publisher is at license.html
Appendix F: Release Notes
The release notes for this version of BFO Publisher are at releasenotes.html
Throughout this document, labels like 1.3 and 1.4 indicate new functionality that has been added in a particular release.